Последние темы
» Вити больше нет!автор bug19 Пн Фев 20 2023, 19:54
» Собираем оригинальный Орион 128
автор bug19 Пн Фев 20 2023, 19:47
» Проблема плющеного экрана ОРИОНА
автор kanzler Пн Ноя 28 2022, 12:05
» Орион 128 и его клоны возрождение 2019-2022 год
автор kanzler Пн Ноя 28 2022, 12:03
» Электроника КР-04. Информация, документы, фото.
автор kanzler Пн Ноя 28 2022, 12:02
» Новости форума
автор kanzler Пн Ноя 28 2022, 11:52
» Орион-128 НГМД запуск 2021 года
автор matrixplus Сб Сен 10 2022, 17:36
» ПЗУ F800 для РК86
автор ведущий_специалист Сб Сен 10 2022, 10:37
» Микропроцессорная лаборатория "Микролаб К580ИК80", УМК-80, УМПК-80 и др.
автор Электротехник Вт Июл 26 2022, 19:33
» Орион-128 SD карта в Орионе
автор matrixplus Чт Июн 02 2022, 09:00
» 7 Мая. День Радио!
автор Viktor2312 Чт Май 12 2022, 10:58
» Серия: Массовая радио библиотека. МРБ
автор Viktor2312 Ср Май 11 2022, 12:17
» Полезные книги
автор Viktor2312 Пн Май 09 2022, 15:07
» Орион 128 Стандарты портов и системной шины Х2
автор matrixplus Вс Май 08 2022, 23:08
» Орион-128 и Орион ПРО еще раз про блоки питания
автор matrixplus Вс Май 08 2022, 19:09
» Орион-128 Программаторы
автор matrixplus Вс Май 08 2022, 19:02
» Орион ПРО история сборки 2021 до 2022
автор matrixplus Вс Май 08 2022, 18:47
» Анонсы монет (New coin).
автор Viktor2312 Сб Май 07 2022, 23:11
» Хочу свой усилок для квартиры собрать не спеша
автор Viktor2312 Сб Май 07 2022, 19:33
» Амфитон 25у-002С
автор Viktor2312 Сб Май 07 2022, 09:38
» Майнер: T-Rex
автор Viktor2312 Вс Май 01 2022, 09:12
» GoWin. Изучение документации. SUG100-2.6E_Gowin Software User Guide. Среда разработки EDA.
автор Viktor2312 Пн Апр 25 2022, 01:01
» GoWin. Изучение документации. UG286-1.9.1E Gowin Clock User Guide.
автор Viktor2312 Сб Апр 23 2022, 18:22
» GoWin. Documentation Database. Device. GW2A.
автор Viktor2312 Ср Апр 20 2022, 14:08
» GOWIN AEC IP
автор Viktor2312 Ср Апр 20 2022, 12:08
Самые активные пользователи за месяц
| Нет пользователей |
Поиск
Мультиклет (MultiClet) всё по порядку...
Страница 1 из 1 • Поделиться

 Мультиклет (MultiClet) всё по порядку...
Мультиклет (MultiClet) всё по порядку...
![]() Viktor2312 Пт Дек 29 2017, 18:56
Viktor2312 Пт Дек 29 2017, 18:56
1
.

ОАО "Мультиклет"
____Разрабатывает процессоры и процессорные ядра на базе мультиклеточной архитектуры.
Мультиклеточная архитектура:
Базовые принципы.
Общие положения.

Архитектуры на базе списка смежности.

БПФ - Быстрое преобразование Фурье.
____Быстрое преобразование Фурье (БПФ, FFT) — алгоритм быстрого вычисления дискретного преобразования Фурье (ДПФ). То есть, алгоритм вычисления за количество действий, меньшее чем O(N2), требуемых для прямого (по формуле) вычисления ДПФ. Иногда под БПФ понимается один из быстрых алгоритмов, называемый алгоритмом прореживания по частоте/времени, имеющий сложность O(N log(N)).
Архитектуры на базе инцидентности.

Фон-неймановская (vN) и мультиклеточная архитектуры.

Мультиклеточная архитектура. Выборка команд и присвоение тегов.

Мультиклеточная архитектура. Формирование программы.
____Команды в программе объединены в параграфы - линейные и информационно-замкнутые последовательности команд.
____Каждый параграф имеет один вход и не менее одного выхода. При наличии нескольких выходов в процессе выполнения должен выполняться только один.
____Состояние процессора меняется, как правило, по завершению параграфа.

Мультиклеточная архитектура. Сравнение программ.

Сравнение архитектур.

.
multiclet.com
Мультиклет (MultiClet)
Мультиклеточная архитектура. Состояние и перспективы.
ОАО "Мультиклет"
____Разрабатывает процессоры и процессорные ядра на базе мультиклеточной архитектуры.
Мультиклеточная архитектура:
- Параллельная, с естественной реализацией параллелизма.
- Универсальная.
- Не Фон-неймановская.
- Не имеет зарубежных аналогов.
- Патентно защищённая.
Базовые принципы.
- Копирование и доработка чужих технических решений - дорога аутсайдеров. В лучшем случае оно консервирует отставание, что подтверждается развитием компьютерной индустрии в нашей стране за последние пятьдесят лет.
- Единственная возможность нашей страны выйти в число лидеров - это разработка своих, принципиально новых и патентно защищённых решений.
Общие положения.
Архитектуры на базе списка смежности.
БПФ - Быстрое преобразование Фурье.
____Быстрое преобразование Фурье (БПФ, FFT) — алгоритм быстрого вычисления дискретного преобразования Фурье (ДПФ). То есть, алгоритм вычисления за количество действий, меньшее чем O(N2), требуемых для прямого (по формуле) вычисления ДПФ. Иногда под БПФ понимается один из быстрых алгоритмов, называемый алгоритмом прореживания по частоте/времени, имеющий сложность O(N log(N)).
Архитектуры на базе инцидентности.
Фон-неймановская (vN) и мультиклеточная архитектуры.
Мультиклеточная архитектура. Выборка команд и присвоение тегов.
Мультиклеточная архитектура. Формирование программы.
____Команды в программе объединены в параграфы - линейные и информационно-замкнутые последовательности команд.
____Каждый параграф имеет один вход и не менее одного выхода. При наличии нескольких выходов в процессе выполнения должен выполняться только один.
____Состояние процессора меняется, как правило, по завершению параграфа.
Мультиклеточная архитектура. Сравнение программ.
Сравнение архитектур.
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск

.
![]() Viktor2312 Сб Дек 30 2017, 02:16
Viktor2312 Сб Дек 30 2017, 02:16
2
Мультиклеточная архитектура. Структура процессора.

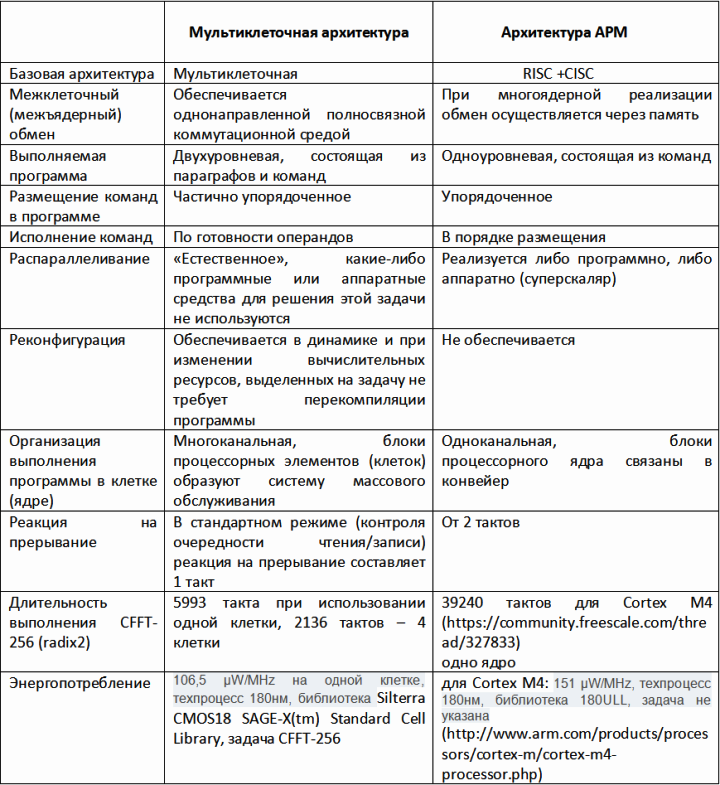
Конкурентные преимущества мультиклеточной архитектуры.
Динамическая реконфигурация.
____Процессоры с мультиклеточной архитектурой - единственный тип процессоров, в которых возможна динамическая реконфигурация процессора в ходе решения потока задач.

task [tɑːsk] - задача.
Производительность на CoreMark.

Производительность на тесте popcnt.
Сводная таблица результатов (количество тактов на один цикл расчёта 32-х бит):

Производительность.

Развитие архитектуры.
.
Конкурентные преимущества мультиклеточной архитектуры.
- Естественная реализация параллелизма (без решения задачи распараллеливания).
- Использование традиционных императивных языков высокого уровня для программирования и типовых инструментальных средств для разработки (LLVM).
- Уменьшение площади кристалла.
- Эффективная реализация любого класса задач (коммутационная среда не накладывает ограничений на межклеточный обмен данными).
- Выполнение программы без перекомпиляции на любом количестве клеток.
- Непрерывное выполнение программы при деградации аппаратной среды (отказах клеток).
- Динамическое перераспределение вычислительных ресурсов.
Динамическая реконфигурация.
____Процессоры с мультиклеточной архитектурой - единственный тип процессоров, в которых возможна динамическая реконфигурация процессора в ходе решения потока задач.
task [tɑːsk] - задача.
Производительность на CoreMark.
Производительность на тесте popcnt.
Сводная таблица результатов (количество тактов на один цикл расчёта 32-х бит):
Производительность.
Развитие архитектуры.
- Для DSP процессоров и процессоров общего назначения - оптимизация схемотехнических решений и, соответственно, уменьшение площади клеток при одновременном повышении их производительности.
- Разработка решений обеспечивающих "живучесть" процессоров в системах с повышенной надёжностью, обеспечивающих непрерывную работу системы при отказах клеток.
- Увеличение количества клеток на кристалле и создание многоуровневых мультиклеточных систем для супервычислений.
Отличия архитектуры мультиклеточного процессора от архитектуры АРМ процессоров.
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск
.
![]() Viktor2312 Сб Дек 30 2017, 03:51
Viktor2312 Сб Дек 30 2017, 03:51
3
Мультиклеточная архитектура:
особенности, реализация и
перспективы развития.
особенности, реализация и
перспективы развития.
1. Введение.
____Результат выполнения процессором любой команды выражается в изменении состояния ряда устройств процессора и/или системы (регистров, шин, ячеек памяти, каналов ввода/вывода и т. д.). Использование этого нового состояния последующими исполняемыми командами, образует информационную связь между командой–источником результата и командами–приёмниками этого результата. Эта информационная связь может быть как непосредственной (прямой), так и опосредованной (косвенной).
____В случае прямой информационной связи команды именуются и при этом имена должны идентифицировать собственно команду, а не её местоположение или другие особенности реализации. Доступ к результатам может осуществляться по именам как команд–источников, так команд–приёмников. В первом случае используется широковещательная рассылка с последующим поименным отбором, при которой в поле операнда команды–приёмника задают имя команды–источника. Во втором – выполняется поименная рассылка, при которой в команде–источнике задают имя команды–приёмника результата.
____При косвенной информационной связи между командами результат доступен только после его отчуждения. А именно, после записи его командой–источником в общедоступные регистры и/или память, имя которых при использовании задают в поле операнда команды–приёмника, или в какие-то другие устройства процессора и/или вычислительной системы, доступ к которым имеют только конкретные команды–приёмники. Например, при адресной рассылке результат записывается по указанным в команде–источнике адресам памяти, в которых находятся команды–приёмники и в указанное поле этих команд.
____Используемые виды информационной связи между командами и характер доступа к результатам являются ключевыми факторами, определяющими архитектурную модель процессора. Именно они определяют не только способы кодирования программ, но также способы и устройства их исполнения. Они также ограничивают количество возможных процессорных моделей четырьмя видами (фон-неймановская, потоковая и две мультиклеточные модели).
2. Процессорные архитектуры с косвенной информационной связью.
____На базе фон-неймановской модели построены все коммерчески успешные процессоры. В её основе лежит общедоступность результатов и, как следствие, решение процессором определенной задачи достигается пошаговым целенаправленным изменением состояния вычислительной системы. Этот процесс изменения состояний является результатом исполнения последовательности команд строго в заданном порядке, который определяют в процессе программирования.
____Как правило, все варианты реализации фон-неймановской модели направлены на решение одной и той же задачи, а именно, повышение производительности процессора, но решают они её разными способами.
____Например, в конвейерных процессорах совмещают выполнение команд во времени при использовании одного исполнительного устройства. В RISC процессорах – сокращают количество функций реализуемых командой и, следовательно, время выполнения одной команды. В CISC процессорах увеличивают объем функций выполняемых одной командой и, соответственно, время, но при этом уменьшают общее количество выполняемых команд.
____За счёт совмещения выполнения команд в пространстве, т.е. на нескольких исполнительных устройствах, обеспечивают повышение производительности суперскалярные процессоры и процессоры со сверхдлинным командным словом (VLIW процессоры). При этом в суперскалярных процессорах задача распределения потока команд по нескольким исполнительным устройствам решается преимущественно аппаратным способом, а в VLIW процессорах – программным, во время компиляции.
____В конкретных реализациях эти и другие способы могут сочетаться. В частности, RISC и CISC процессоры обычно имеют конвейерную организацию, но отличаются друг от друга длиной конвейера. Конвейер также широко используется для сокращения времени выполнения потока команд поступающих к исполнительному устройству в суперскалярных процессорах. Наиболее совершенные способы организации конвейера не только реализуют совмещение выполнения потока команд во времени, но и обеспечивают переупорядочивание команд в конвейере для устранения конфликтов по данным между ступенями конвейера. В этом случае команда в конвейере выполняется не по очередности, а по готовности.
____Известны две схемы, осуществляющие такое переупорядочивание команд. Это схема централизованного окна команд и распределенная схема Томасуло.
____Следует отметить, что ни использование методов распараллеливания в суперскалярных или в VLIW процессорах, ни методов переупорядочивания команд в конвейере, которые меняют очередность исполнения команд – не отменяют ключевого принципа фон-неймановской модели – упорядоченного изменения состояния процессора. Вне зависимости от очередности исполнения команд, формируемые ими состояния процессора меняются в той последовательности, в которой эти команды были выбраны из памяти, а не исполнены.
____Несмотря на разнообразие реализаций, все процессорные устройства, использующие фон-неймановскую модель архитектуры, имеют один общий недостаток.
____Это необходимость решения сложной задачи распараллеливания для организации параллельной работы как внутри процессора, при наличии нескольких однотипных исполнительных устройств, так и при использовании многоядерных процессоров или многопроцессорной вычислительной системы.
____В потоковой модели используется адресный способ связи. Это либо рассылка результатов в потоковых процессорах, либо указание на адрес источника результата в редукционных процессорах. Типичная команда потокового процессора, например, двухместная арифметическая операция, содержит, как правило, код операции, поля операндов, поле адреса команды, которой передаётся результат выполненной операции, и поле номера операнда, в котором он будет размещён. Команда выбирается и выполняется «по готовности операндов», т.е. тогда, когда ею будут получены все результаты выполнения других команд, необходимые для её выполнения. Таким образом, команды в программе могут быть размещены произвольным образом. Принцип исполнения команд потокового процессора «по готовности операндов» позволяет реализовать параллелизм «естественным» образом, т.е. без необходимости решения задачи распараллеливания, но требует для этого использования специальных языков программирования (языков с однократным присваиванием), а также, по сравнению с фон-неймановской моделью, приводит к резкому увеличению затрат на пересылку операндов и выполнению лишних вычислений.
____Многочисленные попытки модифицирования архитектуры потоковых процессоров приводили к решению локальных проблем, не изменяя сути данного метода. Например, ввод тегов для обеспечения реентерабельности подпрограмм или для параллельного выполнения различных итераций цикла является виртуальным расширением адреса («адрес» & «тег»), но не сменой парадигмы.
____Учитывая большой объём существующего в настоящее время программного обеспечения, написанного на традиционных императивных языках, необходимость использования языков с однократным присваиванием для программирования потоковых процессоров делает их применение экономически нецелесообразным.
____Редукционная модель процессора также использует адресную связь между командами, но она задается указанием в поле операнда команды–приёмника адреса команды–источника, которую необходимо выполнить для получения требуемого результата. В этом случае команды выбираются из памяти и исполняются «по запросу команды» Такая модель принципиально не имеет лишних вычислений и также позволяет отказаться от упорядоченности команд, которые могут быть размещены в памяти произвольным образом.
____Как и потоковая, редукционная модель обеспечивает «естественную» реализацию параллелизма, но тоже требует применения для программирования специальных языков, а именно языков функционального программирования. Это требование, как и аналогичное требование к потоковой модели, не позволяет использовать существующее программное обеспечение, что делает использование редукционных процессоров экономически невыгодным. Следует также отметить, что выборка команд «по запросу» ограничивает возможности совмещения по времени процессов выборки и исполнения команд и, как следствие, их параллельную реализацию.
____Разноплановость преимуществ, присущих разным моделям, привела к созданию процессорных моделей, сочетающих различные способы реализации параллелизма и управления вычислительным процессом. Наиболее известные из них – это макропотоковые, и их развитие – гиперпотоковые процессоры.
____В макропотоковых моделях исполнение «по готовности» относится не к одной команде, а к последовательности из нескольких команд, называемых нитью (thread). При этом последовательность команд в пределах нити статична и определена при компиляции, при этом характер её выполнения фон-неймановский. Как правило, для этого используется конвейерная организация. Порядок обработки нитей зависит от их готовности и меняется динамически в процессе вычислений.
____Известны две формы макропотоковой обработки: без блокирования и с блокированием. В модели без блокирования выполнение нити начинается только после получения всех необходимых данных. При этом выполнение нити не прерывается, она выполняется до конца без остановки. В варианте с блокированием выполнение нити может быть начато до получения всех операндов, при этом, когда требуется отсутствующий операнд, выполнение нити приостанавливается (блокируется). Процессор запоминает всю необходимую информацию о состоянии такой заблокированной нити и начинает выполнение другой готовой нити. После получения отсутствующего операнда и завершения выполнения текущей нити, выполнение блокированной нити возобновляется. Модель с блокированием обеспечивает более полную загрузку исполнительных устройств за счет использования механизма блокировки и, как следствие, возможности формирования длинных нитей.
____Гиперпотоковые модели эмулируют работу нескольких логических процессоров на одном вычислительном ядре. При этом в процессе компиляции формируются такие последовательности команд, которые процессор мог бы обрабатывать параллельно, занимая исполнительные устройства, не занятые одним из потоков, подходящими командами из другого независимого потока. Это принципиальное отличие гиперпотоковых моделей от макропотоковых. При этом характер выполнения потока логическим процессором – фон-неймановский, а управление исполнением потоков осуществляется с помощью операционной системы.
____Сочетанием применяемых методов отличается и проект процессора TRIPS, архитектуру которого авторы относят к EDGE-архитектуре – явного исполнения графа потока данных. Процессор TRIPS имеет два функциональных блока, каждый из которых является фактически VLIW процессором, содержащим 16 (4х4) 64-разрядных арифметико-логических устройств (АЛУ) с плавающей точкой и управляемым потоком данных. От традиционного потокового процессора они отличаются тем, что команды загружаются во все АЛУ одновременно, но процесс их выполнения такой же как в потоковом процессоре – асинхронный, по готовности операндов.
____Разные методы используют и в синергической вычислительной системе – синпьютере, который как и процессор TRIPS имеет асинхронную организацию, но в отличие от него состоит из множества идентичных, функционально полных вычислительных устройств, объединенных коммутационной средой, обеспечивающей обмен результатами между ними. Для программирования синпьютера алгоритм рассматривается как совокупность формул, представленных в ярусно-параллельной форме, а именно, в виде ациклического ориентированного графа, вершины которого взаимно-однозначно соответствуют используемым в формуле величинам и операциям, а дуги соответствуют и отражают направление информационных связей между ними. При этом вершины распределены по ярусам (подмножествам) так, что вершины одного яруса непосредственно не связаны друг с другом, а ярусы пронумерованы таким образом, что вершины-источники всегда размещены на вышележащем ярусе (имеющем номер меньше).
____Местоположение любого узла ярусно-параллельной формы задается парой чисел (i, k), где: i – номер яруса (строки); k – номер узла в ярусе (столбца).
____В общем случае, для выполнения операций, расположенных на i-ом ярусе, могут использоваться результаты, полученные на ярусах от 1-го до (i-1)-го. В синергической вычислительной системе эта возможность ограничена следующим образом:
____для выполнения операций на i-ом ярусе используются только результаты (i-1)-го яруса;
____если для выполнения операции на i-ом ярусе нужен результат с яруса j,
где 1 <= j < (i-1), то на ярусе j+1 этот результат запоминается в регистровой или оперативной памяти, а на ярусе i-1 читается.
____Это ограничение позволяет исключить из указания источника результата номер яруса. Источник однозначно задаётся номером узла в предшествующем ярусе и, таким образом, для кодирования двухместных операций достаточно двух полей операндов, содержащих номера узлов источников, результаты которых используются в качестве аргументов при выполнении данной операции. Например, в таблице 1 приведена программа синпьютера для вычисления формулы g = e * (a + b) + (a - c) / f.

____В синпьютере, последовательность описаний операций одного узла является упорядоченной последовательностью команд, выполняемых вычислительным устройством с соответствующим номером. При этом операции одного яруса в принципе могут размещаться произвольно – в любом узле. На них не накладывается требование упорядоченности. Возможность неупорядоченного размещения команд в одном ярусе упрощает решение задачи распараллеливания, но не позволяет реализовать параллелизм «естественным» путем.
____Каждое вычислительное устройство состоит из памяти программ, памяти данных, блока регистров общего назначения и процессора, включающего устройство управления и несколько попарно связанных буферных и исполнительных устройств.
____Устройство управления реализует классическую фон-неймановскую схему выбора команд, т. е. их последовательность определяется счетчиком команд. Буферные устройства обеспечивают хранение выбранных команд до получения всех операндов и передачу готовых команд на исполнение. Исполнительные устройства выполняют готовые команды и передают их результат в коммутационную среду.
____В процессе выборки команд устройства управления всех вычислительных устройств согласованно выбирают команды очередного яруса и присваивают им значения тегов, равные последовательному номеру выбранного яруса. Декодируют выбранные команды и, при необходимости, формируют заявку коммутационной среде на необходимые им результаты вычислительных устройств, полученные при выполнении команд предыдущего яруса, указывая коммутационной среде номер тега предыдущего яруса и номера вычислительных устройств, после чего записывают выбранную команду, в буферное устройство. Выбор буферного устройства определяется выполняемой операцией. Затем формируют новое значение счетчика команд, и процесс выборки повторяется.
____В буферном устройстве команда будет находиться до тех пор, пока она не будет сформирована, а именно, пока коммутационная среда не получит и не передаст в буфер все запрошенные при выборке данной команды результаты.
____Процесс формирования команд инициализируется поступлением в коммутатор очередного результата. При этом коммутационная среда по тегу результата проверяет наличие заявок на данный результат от данного вычислительного устройства. Если заявки есть, то результат передается в буферные устройства соответствующих вычислительных устройств, которые записывают его в поля операндов тех команд, которые его запрашивали.
____Процесс исполнения команды и рассылки результатов инициализируется, если в буферном устройстве есть хотя бы одна команда, у которой получены все операнды (исполнение «по готовности»), и которая не является последней выбранной командой (кроме команды остановки). При этом, если готовых к исполнению команд несколько, то на исполнение передается команда, которая из них была выбрана первой. Исполнительное устройство выполняет команду и выдает в коммутатор её результат вместе с тегом команды.
____Завершается или приостанавливается этот процесс тогда, когда в буферных устройствах нет готовых к исполнению команд.
____Использование принципа исполнения команд «по готовности» в синпьютере и в процессоре TRIPS – не позволяет отнести их к потоковым процессорам. Характер размещения команд и их выборки на исполнение – фон-неймановский. Принцип «по готовности» ограничен только этапом исполнения команд. Соответственно, указанный недостаток фон-неймановской архитектуры присущ обоим процессорам.
____Следует также отметить, что ряд общих недостатков имеют все процессорные устройства, использующие косвенную информационную связь с любым принципом доступа к результатам и, соответственно, с любой архитектурной моделью.
____Это, во-первых, полная машинная зависимость программ. При изменении конфигурации процессора или вычислительной системы, например, при изменении количества используемых исполнительных устройств, как правило, требуется перекомпиляция программ, а иногда и полное перепрограммирование.
____Во-вторых, непрерывное увеличение семантического разрыва между постоянно развиваемыми языками программирования высокого уровня и машинным кодом. В результате повышается сложность компиляторов и, следовательно, затраты на их разработку.
____Указанные недостатки, как и недостаток фон-неймановской архитектуры, связанный с необходимостью решения задачи распараллеливания, возникли из-за использования косвенной информационной связи между командами и, следовательно, они не устранимы в процессорных устройствах, использующих эту связь.
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск
.
![]() Viktor2312 Сб Дек 30 2017, 18:43
Viktor2312 Сб Дек 30 2017, 18:43
4
3. Организация непосредственной информационной связи между командами.
____Принципиально иной вид информационной связи между командами – это непосредственная связь. Примером кодирования программы с использованием этой связи между командами является язык триад, используемый в качестве промежуточного представления исходной программы в процессе компиляции.
____Промежуточное представление в виде триад образуется записями с тремя полями:
<op><arg1><arg2>,
где: op – поле кода операции; arg1 – поле первого операнда; arg2 – поле второго операнда.
____В качестве операндов используются, либо указатели на таблицу символов (для имен, определенных программистом, или констант), либо указатели на триады–источники используемых результатов.
____Для следующей последовательности операторов, написанной на языке высокого уровня и образующей линейный участок:
L1: a:=b+c;
___i:=a*f–g;
___a:=i /h;
___goto L2;
____Промежуточное представление на языке триад будет выглядеть так, как показано в таблице 2.
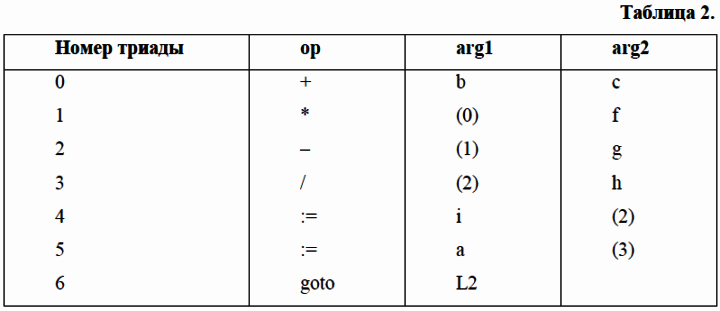
____Имена – это указатели на таблицу символов, а числа в скобках – это указатели (ссылки) на триады, причем допустима только ссылка на триады данного линейного участка. Информационная связь между различными линейными участками – косвенная – через память.
____Использование непосредственных информационных связей между командами и широковещательная рассылка их результатов является принципиальной основой существующей мультиклеточной архитектуры. Система команд мультиклеточного процессора подобна триадам и, фактически, является аппаратной реализацией входного языка программирования.
____Как известно, моделью вычислений в императивных языках высокого уровня является выполнение упорядоченной последовательности операторов. Каждый оператор представляет собой неделимую и целостную языковую конструкцию, описывающую процесс преобразования данных. Порядок выполнения операций внутри оператора задается путем их ранжирования и расстановки скобок, т. е. указанием непосредственных информационных связей между операциями. Промежуточные результаты вычислений внутри оператора не отчуждаются, а программисту виден только результат выполнения оператора. Следовательно, для абстрактной машины, непосредственно реализующий некоторый язык высокого уровня, оператор языка является командой.
____Традиционно, под командой понимается то неделимое и целостное действие вычислительной машины, которое видимо и доступно программисту; оно не может быть задано или выполнено частично (неделимость и целостность); результат данного действия фиксируется путём изменения состояния машины, которое далее может использоваться другими командами (видимость); программист может задавать это действие в процессе программирования (доступность).
____В машинах с фон-неймановской архитектурой система команд машины, которая используется при программировании, полностью эквивалентна системе команд, которую реализуют исполнительные устройства данной машины. Для виртуальной машины, реализующий некоторый язык высокого уровня на аппаратном уровне, ситуация принципиально отличается.
____Так, исходное множество операций любого алгоритмического языка изначально зафиксировано и конечно. Множество операторов, которые теоретически могут быть сконструированы с использованием данных операций, является потенциально бесконечным. Поэтому машина с архитектурой, непосредственно реализующей язык высокого уровня, будет иметь конечный набор команд исполнительных устройств, реализующих множество операций языка, но не будет иметь фиксированной системы команд на уровне машины. Например, команда сложения, реализующая соответствующую операцию, является таковой только внутри машины, но она не является оператором и, соответственно, командой при программировании, где она может быть только составной частью арифметического выражения, используемого в условных операторах или операторах присваивания.
____Устранение этого семантического разрыва между уровнем программирования (оператор) и уровнем исполнения (последовательность команд) для фон-неймановских машин традиционно решается в процессе компиляции. Однако решение этой задачи аппаратными средствами в процессе исполнения более эффективно, поскольку появляется степень свободы в формировании потока команд, поступающего на исполнение. Это позволяет сформировать поток оптимальным образом, исходя из текущего состояния машины.
____Программа мультиклеточного процессора представляет собой неупорядоченную совокупность параграфов, каждый из которых является линейным участком. Информационная связь между командами внутри параграфа – прямая, с широковещательной рассылкой и последующим поименным отбором результатов, а между параграфами связь косвенная, через память. Команды параграфа образуют частично упорядоченную и информационно замкнутую последовательность, а именно, команды–источники предшествуют своим командам-приёмникам, а команды–приёмники имеют ссылки на команды-источники только своего параграфа.
____Состояние мультиклеточного процессора, видимое программисту, формируется по завершению параграфа. В этом смысле, параграф эквивалентен команде в фон-неймановском процессоре или оператору (линейной последовательности операторов) в виртуальной машине, непосредственно реализующей язык высокого уровня. Параграфы в программе не упорядочены. Переход от одного параграфа к другому выполняется только командами передачи управления. Поскольку состояние процессора меняется по завершению параграфа, то команда, формирующая адрес следующего параграфа, может занимать любое место в последовательности команд, образующих параграф.
____Ссылки кодируются числом, значение которого равно разнице между номерами команды-приёмника и команды-источника, полученными при последовательной нумерации команд параграфа. Так, например, фрагмент программы, приведенный в таблице 2, будет выглядеть следующим образом (см. таблицу 3).

____Последнюю команду параграфа отмечают управляющим признаком «конец параграфа». Максимальное значение ссылки (окно видимости результата исполненной команды) определяется размером её поля в команде и равно 2**р–1, где р – размер поля ссылки в битах.
4. Мультиклеточная архитектура.
____Контекстно-зависимая программа выполняется мультиклеточным процессором (см. рис. 1), состоящим из N идентичных клеток с номерами от 0 до n–1, объединенных коммутационной средой. Каждая клетка содержит блок памяти программ (PM), устройство управления (CU), буферные устройства (BUF), а также каждой клетке соответствует коммутационное устройство (SU), совокупность которых образует коммутационную среду (SB).

____Процесс исполнения программы мультиклеточным процессором аналогичен процессу исполнения программы в синпьютере. Основные отличия заключаются в размещении программы в памяти программ, определении по ссылке индивидуальных номеров для каждого запрошенного результата и использовании общих блока памяти данных и блока регистров общего назначения.
____Для исполнения контекстно-зависимой программы, команды каждого параграфа последовательно, начиная с одного и того же адреса, являющегося адресом данного параграфа, размещают в PM (памяти программ) клеток. Адрес размещения первого исполняемого параграфа равен адресу, начиная с которого клетки выбирают команды. В результате, в PM i–ой клетки, начиная с адреса параграфа, последовательно размещаются его команды с номерами i, N+i, 2*N+i,...,.
____Каждая клетка обеспечивает, начиная с указанного ей адреса, последовательную выборку команд и размещение их в регистре команд для последующего декодирования. Команды клетками выбираются синхронно.
____Необходимыми условиями декодирования очередной команды являются завершение декодирования предыдущей команды всеми клетками, считывание и размещение в регистре команд всеми клетками очередной команды и готовность буферных устройств всех клеток к размещению микрокоманд (наличие свободных строк для записи микрокоманд). Если эти условия выполняются, команду декодируют и размещают в буферных устройствах.
____При декодировании каждой очередной выбранной группе из N команд присваивают очередное значение тега (t), а команде из группы и, соответственно, её результату – номер. Значение очередного тега формируется клетками синхронно и изменяется циклически от 0 до Tmax –1, где Tmax=2**p. Минимальное значение Tmax, при котором принципиально невозможна взаимоблокировка команд, определяется размером окна видимости результатов и для N=2**k равно W/N, где W=2**q – размер окна видимости, q – размер поля ссылки в команде в битах.
____
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск

 Похожие темы
Похожие темы» MULTICLET P1
» MULTICLET R1
» Новости про и о Мультиклет!
» Что такое мультиклет. Общая техническая информация
» MULTICLET R1
» Новости про и о Мультиклет!
» Что такое мультиклет. Общая техническая информация
Страница 1 из 1
Права доступа к этому форуму:
Вы не можете отвечать на сообщения