Последние темы
» Вити больше нет!автор bug19 Пн Фев 20 2023, 19:54
» Собираем оригинальный Орион 128
автор bug19 Пн Фев 20 2023, 19:47
» Проблема плющеного экрана ОРИОНА
автор kanzler Пн Ноя 28 2022, 12:05
» Орион 128 и его клоны возрождение 2019-2022 год
автор kanzler Пн Ноя 28 2022, 12:03
» Электроника КР-04. Информация, документы, фото.
автор kanzler Пн Ноя 28 2022, 12:02
» Новости форума
автор kanzler Пн Ноя 28 2022, 11:52
» Орион-128 НГМД запуск 2021 года
автор matrixplus Сб Сен 10 2022, 17:36
» ПЗУ F800 для РК86
автор ведущий_специалист Сб Сен 10 2022, 10:37
» Микропроцессорная лаборатория "Микролаб К580ИК80", УМК-80, УМПК-80 и др.
автор Электротехник Вт Июл 26 2022, 19:33
» Орион-128 SD карта в Орионе
автор matrixplus Чт Июн 02 2022, 09:00
» 7 Мая. День Радио!
автор Viktor2312 Чт Май 12 2022, 10:58
» Серия: Массовая радио библиотека. МРБ
автор Viktor2312 Ср Май 11 2022, 12:17
» Полезные книги
автор Viktor2312 Пн Май 09 2022, 15:07
» Орион 128 Стандарты портов и системной шины Х2
автор matrixplus Вс Май 08 2022, 23:08
» Орион-128 и Орион ПРО еще раз про блоки питания
автор matrixplus Вс Май 08 2022, 19:09
» Орион-128 Программаторы
автор matrixplus Вс Май 08 2022, 19:02
» Орион ПРО история сборки 2021 до 2022
автор matrixplus Вс Май 08 2022, 18:47
» Анонсы монет (New coin).
автор Viktor2312 Сб Май 07 2022, 23:11
» Хочу свой усилок для квартиры собрать не спеша
автор Viktor2312 Сб Май 07 2022, 19:33
» Амфитон 25у-002С
автор Viktor2312 Сб Май 07 2022, 09:38
» Майнер: T-Rex
автор Viktor2312 Вс Май 01 2022, 09:12
» GoWin. Изучение документации. SUG100-2.6E_Gowin Software User Guide. Среда разработки EDA.
автор Viktor2312 Пн Апр 25 2022, 01:01
» GoWin. Изучение документации. UG286-1.9.1E Gowin Clock User Guide.
автор Viktor2312 Сб Апр 23 2022, 18:22
» GoWin. Documentation Database. Device. GW2A.
автор Viktor2312 Ср Апр 20 2022, 14:08
» GOWIN AEC IP
автор Viktor2312 Ср Апр 20 2022, 12:08
Самые активные пользователи за месяц
| Нет пользователей |
Поиск
Статьи, заметки, очерки, разное...
Страница 1 из 1 • Поделиться

 Статьи, заметки, очерки, разное...
Статьи, заметки, очерки, разное...
![]() Viktor2312 Пт Сен 23 2016, 19:15
Viktor2312 Пт Сен 23 2016, 19:15
1
Cost-Optimized Backgrounder
A Cost-Optimized FPGA & SoC Portfolio for Part or All of Your System

Скачать
.
A Cost-Optimized FPGA & SoC Portfolio for Part or All of Your System
Скачать
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск

.
![]() Viktor2312 Вт Авг 14 2018, 09:36
Viktor2312 Вт Авг 14 2018, 09:36
2
.
____Компания Xilinx приобрела китайский стартап DeePhi Technology Co., Ltd., разрабатывающий решения в области машинного обучения на аппаратной базе Xilinx. Нейронные сети, разработанные компанией, были оптимизированы под «железо» Xilinx, что позволило достичь прорывной производительности одновременно с лучшей энергоэффективностью в своём классе.
____Ключевым продуктом DeePhi является архитектура «Аристотель» на основе микросхем ПЛИС Xilinx, которая используется для вычислений свёрточных нейронных сетей (CNN). В данный момент продукт используется для задач по обработке изображений и видео в камерах слежения и видеорегистраторах, но данная архитектура настолько гибка, что может найти применение абсолютно во всём, начиная от смартфонов и заканчивая серверами.
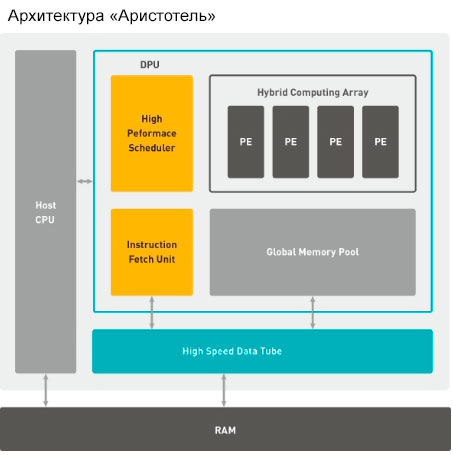
____Например, сейчас решение для видеорегистраторов может анализировать до девяти видеоканалов в формате Full HD в режиме реального времени и может моделировать более тридцати человеческих лиц в одном кадре. Очевидно, что данная платформа имеет широкий круг применений, и, возможно, именно это стало причиной, по которой Xilinx решила приобрести компанию.
____«Мы рады продолжить наше прочное партнёрство с Xilinx и работать ещё более тесно, чтобы предоставить нашим клиентам в Китае и во всём мире ведущие решения для машинного обучения», – сделал заявление генеральный директор DeePhi Tech Сонг Яо.
.
Xilinx приобрела разработчика нейронных сетей DeePhi Technology.
08.08.2018, 14:15
____Компания Xilinx приобрела китайский стартап DeePhi Technology Co., Ltd., разрабатывающий решения в области машинного обучения на аппаратной базе Xilinx. Нейронные сети, разработанные компанией, были оптимизированы под «железо» Xilinx, что позволило достичь прорывной производительности одновременно с лучшей энергоэффективностью в своём классе.
____Ключевым продуктом DeePhi является архитектура «Аристотель» на основе микросхем ПЛИС Xilinx, которая используется для вычислений свёрточных нейронных сетей (CNN). В данный момент продукт используется для задач по обработке изображений и видео в камерах слежения и видеорегистраторах, но данная архитектура настолько гибка, что может найти применение абсолютно во всём, начиная от смартфонов и заканчивая серверами.
____Например, сейчас решение для видеорегистраторов может анализировать до девяти видеоканалов в формате Full HD в режиме реального времени и может моделировать более тридцати человеческих лиц в одном кадре. Очевидно, что данная платформа имеет широкий круг применений, и, возможно, именно это стало причиной, по которой Xilinx решила приобрести компанию.
____«Мы рады продолжить наше прочное партнёрство с Xilinx и работать ещё более тесно, чтобы предоставить нашим клиентам в Китае и во всём мире ведущие решения для машинного обучения», – сделал заявление генеральный директор DeePhi Tech Сонг Яо.
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск
Re: Статьи, заметки, очерки, разное...
![]() Viktor2312 Вт Окт 23 2018, 10:38
Viktor2312 Вт Окт 23 2018, 10:38
3
.
____Компания Xilinx представила PCIe платы для центров обработки данных и облачных вычислений – Xilinx ALVEO.

____Платы разработаны для удовлетворения постоянно растущих потребностей современных центров обработки информации. Xilinx ALVEO обеспечивают производительность в 90 раз больше, чем центральные процессоры в таких задачах, как: машинное обучение, кодирование видео, обработка массивов данных и анализ.
____Тесты производительности Xilinx ALVEO в сравнении с решением на CPU Intel:

Ключевые особенности платы Xilinx ALVEO:
____Компания Xilinx оптимизировала плату ускорителя ALVEO для непрерывной работы 24/7 и даёт на неё гарантию 3 года.
____Платы серии ALVEO представлены в двух вариантах: U200 и U250. Максимальное энергопотребление ALVEO U200/U250 составляет 225 Вт. Также для данных плат доступны готовые решения, значительно упрощающие разработку.


источник
.
PCIe плата для центров обработки данных и облачных вычислений Xilinx ALVEO.
____Компания Xilinx представила PCIe платы для центров обработки данных и облачных вычислений – Xilinx ALVEO.

____Платы разработаны для удовлетворения постоянно растущих потребностей современных центров обработки информации. Xilinx ALVEO обеспечивают производительность в 90 раз больше, чем центральные процессоры в таких задачах, как: машинное обучение, кодирование видео, обработка массивов данных и анализ.
____Тесты производительности Xilinx ALVEO в сравнении с решением на CPU Intel:

Ключевые особенности платы Xilinx ALVEO:
- до 90 раз выше показатели производительности по равнению с CPU при меньшей эквивалентной стоимости;
- пропускная способность до 3 раз выше и 3-кратное преимущество по задержкам по сравнению с решениями на GPU;
- одна и та же плата может быть использована для задач от обработки видео до машинного обучения;
- реконфигурируемое поле FPGA дает лучшую и быструю адаптируемость под различные задачи по сравнению с решениями, построенными на фиксированной архитектуре;
- развёртывание решений взаимозаменяемо и возможно как в облаке, так и локально, что даёт масштабируемость решения в соответствии с требованиями приложений;
- создание своих собственных решений или использование готовых приложений.
____Компания Xilinx оптимизировала плату ускорителя ALVEO для непрерывной работы 24/7 и даёт на неё гарантию 3 года.
____Платы серии ALVEO представлены в двух вариантах: U200 и U250. Максимальное энергопотребление ALVEO U200/U250 составляет 225 Вт. Также для данных плат доступны готовые решения, значительно упрощающие разработку.


источник
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск
Микроконтроллер ARM в любую микросхему ПЛИС Xilinx.
![]() Viktor2312 Вт Ноя 13 2018, 11:34
Viktor2312 Вт Ноя 13 2018, 11:34
4
.
____Компания ARM в рамках сотрудничества с компанией Xilinx представила IP-ядра Cortex-M1 и Cortex-M3 для имплементации в микросхемы ПЛИС Xilinx. Ядра предоставляются в рамках программы ArmDesignStart бесплатно, а их применение не требует лицензионных и каких-либо иных отчислений.

____Загруженные с сайта ARM ядра интегрируются в IP-каталог САПР Vivado, откуда могут быть извлечены и имплементированы в пользовательский проект «в один клик». Являясь soft-IP-cores, данные ядра могут быть имплементированы в практически любую микросхему ПЛИС Xilinx подходящего объёма.
____В отличие от аппаратно реализованных в семействах Zynq-7000 и Zynq Ultrascale Plus ядер, семейство Cortex-M от ARM ориентировано на применение в микроконтроллерах. Оно оптимизировано по ресурсам, не требует внешней памяти и полностью исключает необходимость применения внешних микроконтроллеров.
____Так же с ядрами можно получить 90-дневную пробную лицензию на интегрированную среду разработки Keil MDK.
____Загрузить IP-ядра от ARM можно самостоятельно, предварительно зарегистрировавшись для участия в программе Arm Design Start. Там же, на сайте ARM, можно ознакомиться с примерами разработки на отладочных платах Xilinx и обучающими материалами, в том числе – посмотреть учебное видео.
____Ядро Cortex-M1 доступно для скачивания уже сейчас, а Cortex-M3 будет доступно уже в этом месяце (ноябрь 2018г.)
За дополнительной информацией обращайтесь на сайты компаний Xilinx и ARM
.
Микроконтроллер ARM в любую микросхему ПЛИС Xilinx.
____Компания ARM в рамках сотрудничества с компанией Xilinx представила IP-ядра Cortex-M1 и Cortex-M3 для имплементации в микросхемы ПЛИС Xilinx. Ядра предоставляются в рамках программы ArmDesignStart бесплатно, а их применение не требует лицензионных и каких-либо иных отчислений.

____Загруженные с сайта ARM ядра интегрируются в IP-каталог САПР Vivado, откуда могут быть извлечены и имплементированы в пользовательский проект «в один клик». Являясь soft-IP-cores, данные ядра могут быть имплементированы в практически любую микросхему ПЛИС Xilinx подходящего объёма.
____В отличие от аппаратно реализованных в семействах Zynq-7000 и Zynq Ultrascale Plus ядер, семейство Cortex-M от ARM ориентировано на применение в микроконтроллерах. Оно оптимизировано по ресурсам, не требует внешней памяти и полностью исключает необходимость применения внешних микроконтроллеров.
____Так же с ядрами можно получить 90-дневную пробную лицензию на интегрированную среду разработки Keil MDK.
____Загрузить IP-ядра от ARM можно самостоятельно, предварительно зарегистрировавшись для участия в программе Arm Design Start. Там же, на сайте ARM, можно ознакомиться с примерами разработки на отладочных платах Xilinx и обучающими материалами, в том числе – посмотреть учебное видео.
____Ядро Cortex-M1 доступно для скачивания уже сейчас, а Cortex-M3 будет доступно уже в этом месяце (ноябрь 2018г.)
За дополнительной информацией обращайтесь на сайты компаний Xilinx и ARM
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск
.
![]() Viktor2312 Сб Янв 26 2019, 00:43
Viktor2312 Сб Янв 26 2019, 00:43
5
.
Развитие архитектур программируемых логических интегральных схем делает необходимым периодическое переосмысление перспективных областей применения этой элементной базы и подходов к проектированию. Приведённые в недавнем анонсе компании Xilinx характеристики новой аппаратной платформы ПЛИС Versal являются основанием для того, чтобы пересмотреть основные направления использования высокопроизводительных интегральных схем с учетом тенденций микроэлектронной отрасли и экономики в целом. В статье рассматриваются перспективные направления применения высокопроизводительных ПЛИС, а также программные и аппаратные инструменты проектирования.
Введение.
____Вопросы применения высокопроизводительной (и дорогостоящей) элементноq базы всегда остаются важными и многоплановыми. Можно представить, что высокая цена микросхем с большой производительностью должна служить залогом высокой потребительской ценности создаваемых на их базе продуктов. Однако каким образом реализовать это на практике? Для столь сложных продуктов, каковыми являются ПЛИС, довольно легко при технически корректном проекте использовать возможности ПЛИС неэффективно или сориентироваться на те применения? для которых используемые разновидности ПЛИС изначально не оптимальны.
____На протяжении всего развития элементной базы высокопроизводительных FPGA компания Xilinx неоднократно проводила специализацию отдельных семейств для преимущественного применения в каких-то областях. Начиная с глобального разделения на недорогие (Spartan) и высокопроизводительные (Virtex) серии, уже в 2004 году с выпуском трёх платформ семейства Virtex‑4 наметилась специализация внутри высокопроизводительных ПЛИС. Для семейства Virtex‑4 этими платформами были LX (общее назначение, прототипирование, ориентация на логику), SX (цифровая обработка данных, ориентация на блоки DSP) и FX («полнофункциональная» платформа с аппаратными ядрами PowerPC и увеличенным числом приёмопередатчиков, ориентированная на высокоскоростные проводные коммуникации). Данное разделение сохранялось вплоть до выхода ПЛИС 7‑й серии, в которой специализация была даже дополнительно усилена. Обращаясь к техническим сведениям, нетрудно увидеть, что классификация проведена именно в сегменте высокопроизводительных ПЛИС, путём добавления нового семейства Kintex, ориентированного на цифровую обработку сигналов.
____Вообще, всё большая ориентация на потребительские сегменты рынка, даже с недешёвыми устройствами, характерна для компании Xilinx. На рис. 1 представлена страница официального веб-сайта Xilinx, посвящённая областям применения микросхем ПЛИС. Для ситуации, сложившейся в 2008 году, среди очевидных применений высокопроизводительных микросхем ПЛИС можно было указать:
____Эти области применения в целом соответствовали основным техническим направлениям, реализованным в базовых платформах серии Virtex. Тем не менее с выходом более дешёвого семейства Kintex, появлением высокоинтегрированных систем на кристалле Zynq и анонсированной платформы Versal открываются возможности для реализации продуктов более широкого спектра употребления.

Рис. 1. Внешний вид страницы веб-сайта компании Xilinx, посвящённой преимущественным областям применения ПЛИС.
____Например, общее направление Industrial/Science/Measurement (ISM) охватывает приборы и устройства, ориентированные на специализированные вычисления, характерные, как следует из названия, для промышленности, науки и измерительной техники. В этих отраслях достаточно часто можно встретить оборудование, предъявляющее нестандартные требования к вычислительной системе обработки данных и управления. Применение промышленных компьютеров на базе CPU x86 или ARM может решать эти задачи лишь частично, на уровне интерфейса пользователя, поскольку общий объём вычислений может требовать производительности в триллионы операций в секунду. Это явно недостижимо для современных процессоров x86 и остаётся под вопросом для GPU (так как зависит от соответствия реализуемых алгоритмов архитектуре GPU) и вполне реализуемо для FPGA.
____Можно обратить внимание на наличие на рис. 1 таких направлений, как автомобильная (Automotive) и потребительская (Consumer) электроника. Несмотря на относительно высокую стоимость ПЛИС как таковых, расширение линейки продукции и появление FPGA и APSOC среднего ценового диапазона (в частности, Zynq‑7000S) оставляет пространство для проектирования потребительской электроники на базе ПЛИС среднего уровня производительности. В данном случае, конечно, речь идёт не о системах высокой степени интеграции — например, мультимедийном центре автомобиля, интегрирующем также видеопотоки с камер кругового обзора, или домашнем центре, совмещающем центр мультимедиа и управление оконечными устройствами «Интернета вещей» (IoT). При необходимости работы с множеством таких устройств суммарная вычислительная и коммуникационная нагрузка, скорее всего, превысит пропускную способность однопроцессорных систем или встраиваемых процессорных модулей, и возможности FPGA/APSOC по реализации параллельно действующих систем на одном кристалле окажутся востребованными.
____На рис. 2 показаны основные тенденции в электронной индустрии, по информации компании Xilinx. В данном случае представлены, разумеется, направления, перспективные с точки зрения применения в них микросхем ПЛИС.

Рис. 2. Современные тенденции в электронной индустрии, по данным компании Xilinx.
Беспроводные сети и программно-зависимое радио.
____На протяжении последних лет направление программно-зависимого радио (SDR, Software-Defined Radio) служит примером динамично развивающейся области, которая пока не демонстрирует эффекта насыщения. Если в настоящий момент можно говорить о существовании сетей 3G/4G, то мобильные сети пятого поколения (5G) предполагаются к реализации в районе 2020 года и их планируемые характеристики демонстрируют дальнейшее увеличение скорости передачи данных и снижение потребляемой мощности. В целом развитие сетей 5G связывается с распространением «Интернета вещей» (Internet of Things, IoT), что предполагает ещё один качественный скачок распространения беспроводных сетей и увеличение спектра их применения.
____Использование высокопроизводительных вычислительных систем в данной области можно рассматривать в первую очередь в контексте реализации базовых станций и оборудования магистрального уровня. В качестве оконечных устройств «Интернета вещей» применение микросхем ПЛИС является неоправданным. В то же время наличие в ПЛИС последних поколений большого количества блоков «умножение с накоплением» позволяет реализовать параллельные цифровые каналы обработки радиосигналов, а интегрированные на кристалл приёмопередатчики обеспечивают стыковку беспроводного и проводного сегмента коммуникационных сетей.
Обработка изображений.
____Довольно большая часть функций по обработке изображений имеет естественный параллелизм вычислений. Это достаточно простое наблюдение с учётом того, что изображения представляют собой двумерный массив пикселов, который может быть разбит на отдельные участки для независимой обработки. Соответственно, применение платформы FPGA для подобных целей может оказаться оправданным, особенно если будут реализованы функции, не вполне оптимальные для GPU. Например, в www.xilinx.com/support/documentation/white_papers/wp490-embedded-vision-int8.pdf приведено исследование применимости 8‑разрядных целочисленных данных в задачах машинного обучения и обработки изображений. Для микросхем ПЛИС можно использовать и другие форматы данных, в том числе явно не поддержанные в GPU. Такой подход предусматривает повышение эффективности использования компонентов DSP48 в ПЛИС, обладающих режимом SIMD, при этом возможности GPU для подобных задач избыточны.
____Часть популярной библиотеки OpenCV поддержана продуктом xfOpenCV, реализующим подмножество функций OpenCV, преимущественно для платформы Zynq. Разработанная компанией Xilinx библиотека позволяет распределять вычислительную нагрузку между процессорной подсистемой микросхем Zynq и аппаратными ускорителями, реализуемыми на базе матрицы программируемых ячеек.
Глубокое обучение.
____Термин «глубокое обучение» (deep learning) напрямую связан с нейросетевыми технологиями. В этой, весьма обширной области существует множество только основных классов нейросетей — перцептроны, свёрточные, рекуррентные нейронные сети и т. д. Интерес к нейронным сетям сохранялся в той или иной степени практически на всём протяжении существования этой технологии. Явное уподобление цифровых нейросетей головному мозгу всегда создавало привлекательную перспективу реализации «мыслящих машин» и более глубокого понимания процессов человеческого мышления. Пласт научно-популярных и даже научно-фантастических материалов на эту тему всегда был достаточно представительным и в ряде случаев даже создавал определенные проблемы для адекватного понимания технически достижимых результатов. Определенный вклад вносили и микросхемы ПЛИС, поскольку большое количество блоков «умножение с накоплением» означает возможность реализации множества цифровых нейронов, а значит, и всё большего приближения к параметрам человеческого мозга, хотя бы по количеству нейронов.
____Тем не менее практические исследования в этом направлении уже в 90‑х годах XX века вызвали некоторое разочарование. Стало понятно, что механистическое наслоение большого количества нейронов не приводит к качественно иным результатам и уж тем более не способствует самопроизвольным проявлениям «мыслительных процессов» в компьютерах. Направление, связанное с реализацией большого количества нейронов, соединяемых множеством связей, получило название коннекционизма и в современной литературе подвергается вполне обоснованной критике. Одна из проблем крупных нейронных сетей заключается в том, что результаты их обучения даже на обучающей выборке большого объёма бывает трудно предсказать. Собственные процессы во внутренних слоях нейросети могут сводить на нет эффект обучения, требовать чрезмерного объема обучающей выборки или приводить к таким негативным явлениям, как паралич сети, блокирующий процесс обучения как таковой. Хороший обзор современного состояния исследований приведен, например, в (Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. СПб, Питер, 2018).
____Одним из возможных выходов является применение многоуровневой сети, где каждый уровень обучается независимо, в том числе с помощью предварительно вычисленных весовых коэффициентов. В дальнейшем дообучение нейросети может быть проведено и локально. Однако для получения ощутимых практических результатов такой подход требует наличия высокопроизводительной вычислительной платформы, чтобы эффект от разделения сети на уровни стал наблюдаемым. Практический интерес к сетям глубокого обучения возник в связи с достижением микроэлектронными устройствами соответствующих показателей производительности — наряду с графическими ускорителями (GPU) и специализированными СБИС (например, тензорный процессор Google TPU) соответствующей производительностью обладают и современные микросхемы ПЛИС. В отличие от аппаратных решений, ПЛИС позволяют также более гибко управлять архитектурой соединений внутри нейросети. В этом вопросе они в целом выигрывают у GPU и TPU (в последнем случае речь идет, например, о фиксированной матрице вычислительных узлов размерностью 256 х 256 в микросхеме Google TPU).
____Компания Xilinx обратила внимание на разработку оптимизированных IP-ядер для нейросетевых вычислений с глубоким обучением, разработав продукт xDNN — Xilinx Deep Neural Network. Он представляет собой инструмент конфигурирования нейросетевых вычислительных узлов, использующих аппаратные возможности матрицы программируемых ресурсов микросхемы ПЛИС для реализации нейросети с глубоким обучением.
Центры обработки данных.
____В современном мире высокопроизводительные вычисления можно ассоциировать не только с суперкомпьютерами, но и с гораздо более распространенными системами, такими как центры обработки данных (ЦОД). Существует даже термин embedded supercomputing, относящийся к системе, где вычислительное устройство с параллельной архитектурой реализуется на базе микросхемы ПЛИС в виде сопроцессора для CPU. Среди аппаратных платформ высокопроизводительных вычислений уже сформировались стабильные направления, основанные на использовании процессоров с архитектурой x86, графических процессоров (GPU) и конфигурируемых систем на базе FPGA. Все эти системы имеют свои характерные особенности, которые обусловливают преимущественные направления их применения.
____Данная область (Data Center на рис. 1) может показаться не вполне подходящей для ПЛИС, поскольку способна ассоциироваться с системами на базе серверных процессоров x86 (Intel Xeon) и GPU. Тем не менее можно рассматривать ПЛИС как третий возможный компонент платформы CPU + GPU + ПЛИС, обеспечивающий дальнейшее расширение функциональных возможностей вычислительной системы.
____Немного неожиданным может показаться применение FPGA для систем хранения данных. В
www.theregister.co.uk/2018/10/19/samsung_7llp_ssd_/
www.smartiops.com/smart-iops-utilizes-xilinxfpgas-to-introduce-the-highest-sustained-nvmessd-performance-for-the-enterprise-data-center/ приведены обзоры модулей, использующих FPGA Xilinx для накопителей типа SSD. Так, в разработку Samsung включена микросхема ПЛИС ZU19EG (Zynq UltraScale+ MPSOC), которую нельзя считать недорогим компонентом. Однако возможности переноса существенной части работы в ПЛИС и снижение трафика между SSD и процессорной подсистемой в данном случае являются определяющим фактором.
Высокопроизводительные вычислительные модули Xilinx Alveo.
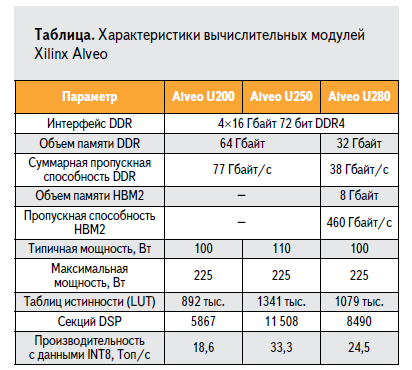
____Для реализации высокопроизводительных систем на базе ПЛИС на недавнем мероприятии Xilinx Developer Forum наряду с новым семейством Versal были анонсированы мощные вычислительные модули Alveo, основанные на ПЛИС UltraScale+ (рис. 3). Модули предназначены для установки в слот PCI Express (и занимают два слота). Характеристики модулей представлены в таблице.
Рис. 3. Вычислительный модуль Xilinx Alveo на базе FPGA UltraScale+.
____В таблице видно, что в одинаковом формфакторе реализована серия вычислительных модулей, обладающих впечатляющей производительностью — десятки триллионов операций в секунду при работе с уже упомянутыми выше данными в целочисленном формате. Возможность подобной специализации в сочетании с высокой пропускной способностью интерфейсов памяти и PCI Express делает модули Alveo чрезвычайно интересным продуктом для использования в качестве ускорителя вычислений. Доступность данных модулей в России может быть обсуждена с официальным дистрибьютором www.plis.ru/docum/xdf_2018/anonsi_xdf_2018_ch2_alveo.
Заключение.
____Исходя из событий 2018 года, включающих анонсированное семейство Xilinx Versal и вычислительные модули Alveo, а также сочетание текущих потребностей российского рынка и возможностей российских разработчиков, можно указать дальнейшие перспективы применения продукции Xilinx. В первую очередь необходимо отложить непосредственное применение в проектах анонсированного семейства Xilinx Versal, поскольку политика ранних анонсов, принятая в современной микроэлектронной индустрии, делает сроки первых поставок трудно предсказуемыми. Появление отладочных плат на базе Versal и возможности заказа образцов этих микросхем необходимо согласовывать с компанией-дистрибьютором, способной обеспечить официальную поставку продукции Xilinx в гарантированные сроки. Далее, современные тенденции рынка делают перспективными проекты технического зрения, программно-зависимого радио и нейронных сетей глубокого обучения на базе микросхем ПЛИС, где они способны в полной мере проявить особенности архитектуры в части параллельной обработки данных. Для эффективного использования высокопроизводительной элементной базы Xilinx рекомендуется обращать внимание на средства проектирования системного уровня и обеспечивать методическое сопровождение проекта, начиная с математических моделей решаемой задачи, проверяемых на ранних этапах, еще до вы- бора конкретного наименования микросхемы ПЛИС.
.
Современные перспективы применения высокопроизводительных ПЛИС Xilinx.
Развитие архитектур программируемых логических интегральных схем делает необходимым периодическое переосмысление перспективных областей применения этой элементной базы и подходов к проектированию. Приведённые в недавнем анонсе компании Xilinx характеристики новой аппаратной платформы ПЛИС Versal являются основанием для того, чтобы пересмотреть основные направления использования высокопроизводительных интегральных схем с учетом тенденций микроэлектронной отрасли и экономики в целом. В статье рассматриваются перспективные направления применения высокопроизводительных ПЛИС, а также программные и аппаратные инструменты проектирования.
Илья Тарасов,
д. т. н.
ilya_e_tarasov@mail.ru
д. т. н.
ilya_e_tarasov@mail.ru
Введение.
____Вопросы применения высокопроизводительной (и дорогостоящей) элементноq базы всегда остаются важными и многоплановыми. Можно представить, что высокая цена микросхем с большой производительностью должна служить залогом высокой потребительской ценности создаваемых на их базе продуктов. Однако каким образом реализовать это на практике? Для столь сложных продуктов, каковыми являются ПЛИС, довольно легко при технически корректном проекте использовать возможности ПЛИС неэффективно или сориентироваться на те применения? для которых используемые разновидности ПЛИС изначально не оптимальны.
____На протяжении всего развития элементной базы высокопроизводительных FPGA компания Xilinx неоднократно проводила специализацию отдельных семейств для преимущественного применения в каких-то областях. Начиная с глобального разделения на недорогие (Spartan) и высокопроизводительные (Virtex) серии, уже в 2004 году с выпуском трёх платформ семейства Virtex‑4 наметилась специализация внутри высокопроизводительных ПЛИС. Для семейства Virtex‑4 этими платформами были LX (общее назначение, прототипирование, ориентация на логику), SX (цифровая обработка данных, ориентация на блоки DSP) и FX («полнофункциональная» платформа с аппаратными ядрами PowerPC и увеличенным числом приёмопередатчиков, ориентированная на высокоскоростные проводные коммуникации). Данное разделение сохранялось вплоть до выхода ПЛИС 7‑й серии, в которой специализация была даже дополнительно усилена. Обращаясь к техническим сведениям, нетрудно увидеть, что классификация проведена именно в сегменте высокопроизводительных ПЛИС, путём добавления нового семейства Kintex, ориентированного на цифровую обработку сигналов.
____Вообще, всё большая ориентация на потребительские сегменты рынка, даже с недешёвыми устройствами, характерна для компании Xilinx. На рис. 1 представлена страница официального веб-сайта Xilinx, посвящённая областям применения микросхем ПЛИС. Для ситуации, сложившейся в 2008 году, среди очевидных применений высокопроизводительных микросхем ПЛИС можно было указать:
- прототипирование (Emulation & Prototyping);
- высокопроизводительные вычисления (High Performance Computing);
- проводные и беспроводные системы связи (Wired/Wireless Communications).
____Эти области применения в целом соответствовали основным техническим направлениям, реализованным в базовых платформах серии Virtex. Тем не менее с выходом более дешёвого семейства Kintex, появлением высокоинтегрированных систем на кристалле Zynq и анонсированной платформы Versal открываются возможности для реализации продуктов более широкого спектра употребления.

Рис. 1. Внешний вид страницы веб-сайта компании Xilinx, посвящённой преимущественным областям применения ПЛИС.
____Например, общее направление Industrial/Science/Measurement (ISM) охватывает приборы и устройства, ориентированные на специализированные вычисления, характерные, как следует из названия, для промышленности, науки и измерительной техники. В этих отраслях достаточно часто можно встретить оборудование, предъявляющее нестандартные требования к вычислительной системе обработки данных и управления. Применение промышленных компьютеров на базе CPU x86 или ARM может решать эти задачи лишь частично, на уровне интерфейса пользователя, поскольку общий объём вычислений может требовать производительности в триллионы операций в секунду. Это явно недостижимо для современных процессоров x86 и остаётся под вопросом для GPU (так как зависит от соответствия реализуемых алгоритмов архитектуре GPU) и вполне реализуемо для FPGA.
____Можно обратить внимание на наличие на рис. 1 таких направлений, как автомобильная (Automotive) и потребительская (Consumer) электроника. Несмотря на относительно высокую стоимость ПЛИС как таковых, расширение линейки продукции и появление FPGA и APSOC среднего ценового диапазона (в частности, Zynq‑7000S) оставляет пространство для проектирования потребительской электроники на базе ПЛИС среднего уровня производительности. В данном случае, конечно, речь идёт не о системах высокой степени интеграции — например, мультимедийном центре автомобиля, интегрирующем также видеопотоки с камер кругового обзора, или домашнем центре, совмещающем центр мультимедиа и управление оконечными устройствами «Интернета вещей» (IoT). При необходимости работы с множеством таких устройств суммарная вычислительная и коммуникационная нагрузка, скорее всего, превысит пропускную способность однопроцессорных систем или встраиваемых процессорных модулей, и возможности FPGA/APSOC по реализации параллельно действующих систем на одном кристалле окажутся востребованными.
____На рис. 2 показаны основные тенденции в электронной индустрии, по информации компании Xilinx. В данном случае представлены, разумеется, направления, перспективные с точки зрения применения в них микросхем ПЛИС.

Рис. 2. Современные тенденции в электронной индустрии, по данным компании Xilinx.
Беспроводные сети и программно-зависимое радио.
____На протяжении последних лет направление программно-зависимого радио (SDR, Software-Defined Radio) служит примером динамично развивающейся области, которая пока не демонстрирует эффекта насыщения. Если в настоящий момент можно говорить о существовании сетей 3G/4G, то мобильные сети пятого поколения (5G) предполагаются к реализации в районе 2020 года и их планируемые характеристики демонстрируют дальнейшее увеличение скорости передачи данных и снижение потребляемой мощности. В целом развитие сетей 5G связывается с распространением «Интернета вещей» (Internet of Things, IoT), что предполагает ещё один качественный скачок распространения беспроводных сетей и увеличение спектра их применения.
____Использование высокопроизводительных вычислительных систем в данной области можно рассматривать в первую очередь в контексте реализации базовых станций и оборудования магистрального уровня. В качестве оконечных устройств «Интернета вещей» применение микросхем ПЛИС является неоправданным. В то же время наличие в ПЛИС последних поколений большого количества блоков «умножение с накоплением» позволяет реализовать параллельные цифровые каналы обработки радиосигналов, а интегрированные на кристалл приёмопередатчики обеспечивают стыковку беспроводного и проводного сегмента коммуникационных сетей.
Обработка изображений.
____Довольно большая часть функций по обработке изображений имеет естественный параллелизм вычислений. Это достаточно простое наблюдение с учётом того, что изображения представляют собой двумерный массив пикселов, который может быть разбит на отдельные участки для независимой обработки. Соответственно, применение платформы FPGA для подобных целей может оказаться оправданным, особенно если будут реализованы функции, не вполне оптимальные для GPU. Например, в www.xilinx.com/support/documentation/white_papers/wp490-embedded-vision-int8.pdf приведено исследование применимости 8‑разрядных целочисленных данных в задачах машинного обучения и обработки изображений. Для микросхем ПЛИС можно использовать и другие форматы данных, в том числе явно не поддержанные в GPU. Такой подход предусматривает повышение эффективности использования компонентов DSP48 в ПЛИС, обладающих режимом SIMD, при этом возможности GPU для подобных задач избыточны.
____Часть популярной библиотеки OpenCV поддержана продуктом xfOpenCV, реализующим подмножество функций OpenCV, преимущественно для платформы Zynq. Разработанная компанией Xilinx библиотека позволяет распределять вычислительную нагрузку между процессорной подсистемой микросхем Zynq и аппаратными ускорителями, реализуемыми на базе матрицы программируемых ячеек.
Глубокое обучение.
____Термин «глубокое обучение» (deep learning) напрямую связан с нейросетевыми технологиями. В этой, весьма обширной области существует множество только основных классов нейросетей — перцептроны, свёрточные, рекуррентные нейронные сети и т. д. Интерес к нейронным сетям сохранялся в той или иной степени практически на всём протяжении существования этой технологии. Явное уподобление цифровых нейросетей головному мозгу всегда создавало привлекательную перспективу реализации «мыслящих машин» и более глубокого понимания процессов человеческого мышления. Пласт научно-популярных и даже научно-фантастических материалов на эту тему всегда был достаточно представительным и в ряде случаев даже создавал определенные проблемы для адекватного понимания технически достижимых результатов. Определенный вклад вносили и микросхемы ПЛИС, поскольку большое количество блоков «умножение с накоплением» означает возможность реализации множества цифровых нейронов, а значит, и всё большего приближения к параметрам человеческого мозга, хотя бы по количеству нейронов.
____Тем не менее практические исследования в этом направлении уже в 90‑х годах XX века вызвали некоторое разочарование. Стало понятно, что механистическое наслоение большого количества нейронов не приводит к качественно иным результатам и уж тем более не способствует самопроизвольным проявлениям «мыслительных процессов» в компьютерах. Направление, связанное с реализацией большого количества нейронов, соединяемых множеством связей, получило название коннекционизма и в современной литературе подвергается вполне обоснованной критике. Одна из проблем крупных нейронных сетей заключается в том, что результаты их обучения даже на обучающей выборке большого объёма бывает трудно предсказать. Собственные процессы во внутренних слоях нейросети могут сводить на нет эффект обучения, требовать чрезмерного объема обучающей выборки или приводить к таким негативным явлениям, как паралич сети, блокирующий процесс обучения как таковой. Хороший обзор современного состояния исследований приведен, например, в (Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. СПб, Питер, 2018).
____Одним из возможных выходов является применение многоуровневой сети, где каждый уровень обучается независимо, в том числе с помощью предварительно вычисленных весовых коэффициентов. В дальнейшем дообучение нейросети может быть проведено и локально. Однако для получения ощутимых практических результатов такой подход требует наличия высокопроизводительной вычислительной платформы, чтобы эффект от разделения сети на уровни стал наблюдаемым. Практический интерес к сетям глубокого обучения возник в связи с достижением микроэлектронными устройствами соответствующих показателей производительности — наряду с графическими ускорителями (GPU) и специализированными СБИС (например, тензорный процессор Google TPU) соответствующей производительностью обладают и современные микросхемы ПЛИС. В отличие от аппаратных решений, ПЛИС позволяют также более гибко управлять архитектурой соединений внутри нейросети. В этом вопросе они в целом выигрывают у GPU и TPU (в последнем случае речь идет, например, о фиксированной матрице вычислительных узлов размерностью 256 х 256 в микросхеме Google TPU).
____Компания Xilinx обратила внимание на разработку оптимизированных IP-ядер для нейросетевых вычислений с глубоким обучением, разработав продукт xDNN — Xilinx Deep Neural Network. Он представляет собой инструмент конфигурирования нейросетевых вычислительных узлов, использующих аппаратные возможности матрицы программируемых ресурсов микросхемы ПЛИС для реализации нейросети с глубоким обучением.
Центры обработки данных.
____В современном мире высокопроизводительные вычисления можно ассоциировать не только с суперкомпьютерами, но и с гораздо более распространенными системами, такими как центры обработки данных (ЦОД). Существует даже термин embedded supercomputing, относящийся к системе, где вычислительное устройство с параллельной архитектурой реализуется на базе микросхемы ПЛИС в виде сопроцессора для CPU. Среди аппаратных платформ высокопроизводительных вычислений уже сформировались стабильные направления, основанные на использовании процессоров с архитектурой x86, графических процессоров (GPU) и конфигурируемых систем на базе FPGA. Все эти системы имеют свои характерные особенности, которые обусловливают преимущественные направления их применения.
____Данная область (Data Center на рис. 1) может показаться не вполне подходящей для ПЛИС, поскольку способна ассоциироваться с системами на базе серверных процессоров x86 (Intel Xeon) и GPU. Тем не менее можно рассматривать ПЛИС как третий возможный компонент платформы CPU + GPU + ПЛИС, обеспечивающий дальнейшее расширение функциональных возможностей вычислительной системы.
____Немного неожиданным может показаться применение FPGA для систем хранения данных. В
www.theregister.co.uk/2018/10/19/samsung_7llp_ssd_/
www.smartiops.com/smart-iops-utilizes-xilinxfpgas-to-introduce-the-highest-sustained-nvmessd-performance-for-the-enterprise-data-center/ приведены обзоры модулей, использующих FPGA Xilinx для накопителей типа SSD. Так, в разработку Samsung включена микросхема ПЛИС ZU19EG (Zynq UltraScale+ MPSOC), которую нельзя считать недорогим компонентом. Однако возможности переноса существенной части работы в ПЛИС и снижение трафика между SSD и процессорной подсистемой в данном случае являются определяющим фактором.
Высокопроизводительные вычислительные модули Xilinx Alveo.
____Для реализации высокопроизводительных систем на базе ПЛИС на недавнем мероприятии Xilinx Developer Forum наряду с новым семейством Versal были анонсированы мощные вычислительные модули Alveo, основанные на ПЛИС UltraScale+ (рис. 3). Модули предназначены для установки в слот PCI Express (и занимают два слота). Характеристики модулей представлены в таблице.
Рис. 3. Вычислительный модуль Xilinx Alveo на базе FPGA UltraScale+.
____В таблице видно, что в одинаковом формфакторе реализована серия вычислительных модулей, обладающих впечатляющей производительностью — десятки триллионов операций в секунду при работе с уже упомянутыми выше данными в целочисленном формате. Возможность подобной специализации в сочетании с высокой пропускной способностью интерфейсов памяти и PCI Express делает модули Alveo чрезвычайно интересным продуктом для использования в качестве ускорителя вычислений. Доступность данных модулей в России может быть обсуждена с официальным дистрибьютором www.plis.ru/docum/xdf_2018/anonsi_xdf_2018_ch2_alveo.

Заключение.
____Исходя из событий 2018 года, включающих анонсированное семейство Xilinx Versal и вычислительные модули Alveo, а также сочетание текущих потребностей российского рынка и возможностей российских разработчиков, можно указать дальнейшие перспективы применения продукции Xilinx. В первую очередь необходимо отложить непосредственное применение в проектах анонсированного семейства Xilinx Versal, поскольку политика ранних анонсов, принятая в современной микроэлектронной индустрии, делает сроки первых поставок трудно предсказуемыми. Появление отладочных плат на базе Versal и возможности заказа образцов этих микросхем необходимо согласовывать с компанией-дистрибьютором, способной обеспечить официальную поставку продукции Xilinx в гарантированные сроки. Далее, современные тенденции рынка делают перспективными проекты технического зрения, программно-зависимого радио и нейронных сетей глубокого обучения на базе микросхем ПЛИС, где они способны в полной мере проявить особенности архитектуры в части параллельной обработки данных. Для эффективного использования высокопроизводительной элементной базы Xilinx рекомендуется обращать внимание на средства проектирования системного уровня и обеспечивать методическое сопровождение проекта, начиная с математических моделей решаемой задачи, проверяемых на ранних этапах, еще до вы- бора конкретного наименования микросхемы ПЛИС.
.
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск
Re: Статьи, заметки, очерки, разное...
![]() Viktor2312 Чт Фев 07 2019, 14:33
Viktor2312 Чт Фев 07 2019, 14:33
6
.
КОМПОНЕНТЫ И ТЕХНОЛОГИИ • № 1 '2019
____Удовлетворение потребностей рынка при использовании процессоров (CPU) или многоядерных процессоров в серверах и центрах обработки данных оказывается затруднительным из-за их возрастающей стоимости, повышенного энергопотребления и размера самих стоек с CPU. Более того, для решения многих задач увеличение количества полностью процессорных серверов не приведёт к достижению желаемой производительности. Ввиду сложностей уменьшения технологического процесса изготовления микросхем не следует особо полагаться на увеличение эффективности за счёт процессоров следующего поколения. Поэтому всё большее внимание уделяется адаптивным ускорителям, которые могут удовлетворить растущие запросы высокопроизводительных вычислений.
Введение.
____В современных условиях, когда всё более совершенные алгоритмы появляются быстрее, чем успевают производиться соответствующие ресурсы с фиксированной функциональностью, такие как ASIC и GPU, рынку необходимы устройства, способные как можно быстрее подстраиваться под изменчивые требования алгоритмов. Карты-ускорители Alveo U200 и U250, созданные на базе самых современных FPGA архитектуры UltraScale+ компании Xilinx, обладают чрезвычайной гибкостью, реконфигурируемостью и адаптируемостью, позволяющей применить их для реализации любых задач.
____Карты-ускорители Alveo специально разработаны для удовлетворения потребностей быстро меняющегося мира высокопроизводительных вычислений ЦОД, что предусматривает достижение 90‑кратного преимущества по сравнению с CPU в таких приложениях, как машинное обучение, видеотранскодинг, поиск и анализ баз данных (WP499. Breathe New Life into Your Data Center with Alveo Adaptable Accelerator Cards — Xilinx Inc. November 19, 2018).
Быстродействие, доступность и адаптируемость.
____Для устранения растущего разрыва между спросом на вычислительные ресурсы и возможностями ЦОД, состоящих только из CPU, компания Xilinx предложила серию специализированных ускорителей Alveo — плат формата PCIe, готовых к установке и работе в ЦОД. На рис. 1 изображена плата-ускоритель Alveo с активным охлаждением (имеется исполнение и с пассивным охлаждением).


Рис. 1. Плата Alveo U250 c активным и пассивным охлаждением.
____Плата-ускоритель — это законченное решение, сочетающее все преимущества микросхем ПЛИС Xilinx:
____Перечисленные преимущества делают карты-ускорители Alveo лидером во многих областях высокопроизводительных вычислений и обработки данных:
____Карты-ускорители U200 и U250 уже выпускаются компанией Xilinx, а карта-ускоритель U280, содержащая ПЛИС с высокопроизводительной памятью HBM, будет доступна в ближайшее время. Следующие поколения карт-ускорителей Alveo будут содержать кристаллы с недавно анонсированной архитектурой Versal:
или адаптируемой платформой ускорения вычислений (ACAP), обладающие ещё большими показателями производительности и эффективности. Например, вычислительные модули AI Engines в архитектуре Versal позволят ускорить приложения машинного обучения до 20 раз.
Быстродействие.
____Карты-ускорители уникальны, поскольку обладают сразу двумя важными достоинствами: высокой пропускной способностью и маленькой задержкой для широкого круга приложений, разворачиваемых в ЦОД. Решения на базе CPU и GPU обычно предполагают компромисс между задержкой и пропускной способностью ввиду ограничений их жесткой архитектуры и программно управляемого потока данных.

Рис. 2. Преимущество карт-ускорителей Alveo перед решениями на CPU.
На рис. 2 отображены некоторые показатели преимущества карт-ускорителей Alveo над решениями на CPU для наиболее ключевых приложений, разворачиваемых в ЦОД. Более детальное описание преимуществ будет приведено далее в статье.
Адаптируемость.
____В отличие от CPU и GPU карты-ускорители Alveo имеют аппаратную адаптируемость, в том смысле, что лежащее в основе аппаратное обеспечение (программируемая логическая интегральная схема — ПЛИС, FPGA) может быть сконфигурировано (реконфигурировано) в зависимости от выполняемой задачи. Решения на CPU и GPU могут предложить только гибкость в плане программного обеспечения, поскольку их аппаратная структура имеет фиксированную архитектуру, которую нельзя изменить. И если решаемая задача такова, что плохо «ложится» на фиксированную архитектуру CPU или GPU, то в этом случае достижение высокой производительности от аппаратуры невозможно.
____Гибкость архитектуры карт-ускорителей Alveo даёт следующие преимущества:
Рис. 3. Адаптируемость Alveo: меньшее количество обновлений оборудования.
____Для разработчиков, желающих построить и адаптировать собственные приложения на картах-ускорителях Alveo, компания Xilinx представляет специализированную среду разработки SDAccel Development environment (www.xilinx.com/products/design-tools/software-zone/sdaccel.html).
Доступность.
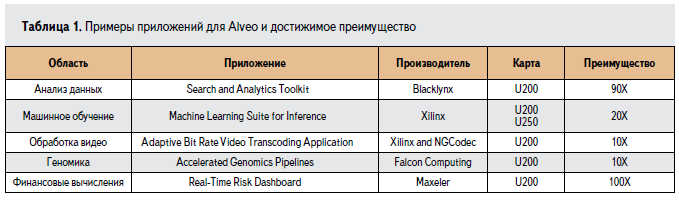
____Для того чтобы предоставить пользователям возможность оценить все преимущества карт-ускорителей Alveo, компания Xilinx совместно с партнерами подготовила ряд приложений. Приложения покрывают ключевые особенности и направления применения карт-ускорителей Alveo, включая развертывание обученных нейронных сетей для задач машинного обучения, транскодинг видеопотоков, анализ и поиск по базам данных, геномику и вычисления в области финансов. В таблице 1 приведена часть списка приложений, доступных на картах-ускорителях Alveo. С полным списком доступных приложений можно ознакомиться на сайте Xilinx (Alveo Accelerator Card Applications. www.xilinx.com/products/acceleration-solutions.html).
____Для апробирования преимуществ технологий и изделий компании Xilinx облачные сервисы, такие как AWS, Nimbix, Alibaba, Baidu, Tancent и Huawei, уже подготовили услугу FaaS (FPGA as a Service) — «FPGA как сервис». Облачные решения предлагают пользователю легкий доступ к апробированию решений Xilinx для ускорения приложений пользователя на картах-ускорителях Alveo, без необходимости разворачивать у себя какой-либо сервер для тестирования преимуществ данных карт. При получении удовлетворительных результатов пользователь может применить карты-ускорители Alveo в собственном сервере. Локальное развертывание решения в общем случае может быть необходимо по различным причинам — например, в случае приложений, где критичным является время вычислений и получение результата.
____Более подробно о сервисе FaaS с использованием продуктов компании Xilinx можно ознакомиться в (Accelerated Cloud Services. www.xilinx.com/products/design-tools/cloud-based-acceleration.html).
Примеры приложений для ЦОД.
____Для обзора преимуществ быстродействия, доступности и адаптируемости карт-ускорителей Alveo проанализируем несколько приложений для ЦОД:
Ускорение задач машинного обучения на Alveo.
____Многие компании получили огромные преимущества после адаптации машинного обучения под свои задачи и технологии. К ним относятся, например, медицинская диагностика, сетевая безопасность, автономное вождение, обработка изображений со спутников. Машинное обучение само по себе является широкой и динамически развивающейся областью. Вместе с тем оно имеет два уникальных этапа:
____Оба этапа чрезвычайно вычислительно затратны. Как следствие, решение на базе только одних CPU оказывается неперспективным ввиду того, что такое решение не может достичь необходимой производительности и требуемой задержки. Да и стоимость и энергозатраты подобного решения становятся несоизмеримо высоки.
____Решения на базе GPU хорошо подходят для задачи обучения нейронной сети, поскольку архитектура GPU содержит большое количество вычислительных модулей, реализующих операции с плавающей запятой. Однако при развёртывании обученной нейронной сети GPU оказываются во многом неподходящим решением. Анализ различий между обучением и развертыванием нейронных сетей позволяет выявить следующие причины, по которым решения на базе GPU могут оказаться неподходящими для этапа Inference:
____Комбинация необходимости быстрого отклика с более высоким коэффициентом передачи данных для вычисления результатов становится реальным вызовом для применения GPU в области развертывания обученных нейронных сетей. Компания Nvidia опубликовала результаты, которые показали, что их флагман Tesla V100 может обработать только 870 изображений/с для сети GoogleNet v1 Batch = 1, что составляет лишь ~2% от теоретической производительности V100 в 40 тыс. изображений/с для обученной сети GoogleNet v1, даже при использовании памяти HBM с пропускной способностью 900 Гбайт/с (Nvidia white paper, Nvidia ai inference platform. www.nvidia.com/en-us/data-center/resources/inference-technical-overview). Для сравнения: развернутая на карте-ускорителе Alveo нейронная сеть GoogLeNet показала производительность, равную 50% от теоретически достижимой при Batch = 1.
____По мере развития нейронных сетей архитектура GPU, вероятно, будет становиться всё более сложной. Как пример — поддержка GPU только определенного типа данных. В случае если необходимо работать с данными меньшей разрядности или произвольной разрядности для улучшения показателей эффективности и пропускной способности, пользователь вынужден дождаться появления новой карты, прежде чем сможет воспользоваться преимуществами реализации нейронной сети с уменьшенной или произвольной точностью. Как результат и как описано в разделе «Адаптируемость» и изображено на рис. 3, решения на базе GPU требуют частого обновления аппаратной части, что приводит к удорожанию оборудования и решения в целом.
____Карты-ускорители Alveo являются более подходящим решением по ряду причин:
____Для того чтобы специалисты могли воспользоваться преимуществами карт-ускорителей Alveo в задачах ML Inference, компанией Xilinx и партнерами было подготовлено несколько решений. Примеры некоторых решений и их сравнение с CPU приведены в таблице 2.
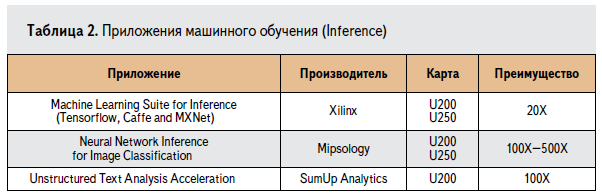
____Для того чтобы лучше понять преимущества карт-ускорителей Alveo в задачах ML Inference, рассмотрим специализированный инструмент ML Suite, разработанный компанией Xilinx для решения именно этой задачи.
Xilinx ML Suite.
____Компания Xilinx создала ML Suite для быстрого развертывания своих ускорителей для работы с обученными свёрточными нейронными сетями (Сonvolution Neural Network — CNN, класс сетей для машинного обучения, используемых для классификации изображений и детектирования объектов). Сердцем ML Suite является вычислительный модуль xDNN (будет рассмотрен далее), реализованный в микросхемах ПЛИС Xilinx, и специализированное промежуточное программное обеспечение xfDNN, позволяющее работать с современными фреймворками машинного обучения через API на языках Python и C++. Подробнее о структуре ML Suite, xfDNN и xDNN будет написано во второй части статьи.
Ускорение анализа и поиска по базам данных.
____Анализ данных — важный инструмент для предприятий. По сути, анализ данных — это получение релевантных данных (поиск), в основном хранящихся в объёмных базах данных, обработка/анализ этих данных для получения информации. Предприятиям нужна возможность быстрее обрабатывать и анализировать большие и неструктурированные наборы данных. Поиск решения этой проблемы при масштабировании вычислительных узлов, содержащих только CPU, может стать проблемой ввиду увеличения стоимости, энергопотребления и плохой масштабируемости данного подхода.
____GPU используются для ускорения ограниченного круга задач поиска и анализа баз данных. Однако преимущества GPU весьма ограничены их фиксированной архитектурой. Многие требования конечных приложений поиска и анализа баз данных расходятся с сегодняшней архитектурой GPU:
____В сравнении с GPU карты-ускорители Alveo имеют возможность аппаратного конфигурирования (реконфигурирования) для выполнения специфической задачи, а возможность прямого подключения к сети передачи данных делает их идеальным ускорителем для широкого круга задач анализа и поиска в базах данных. Эти преимущества приводят к более быстрому решению, требующему меньше аппаратного обеспечения и потребляемой мощности, что в итоге положительно сказывается на стоимости решения в целом.
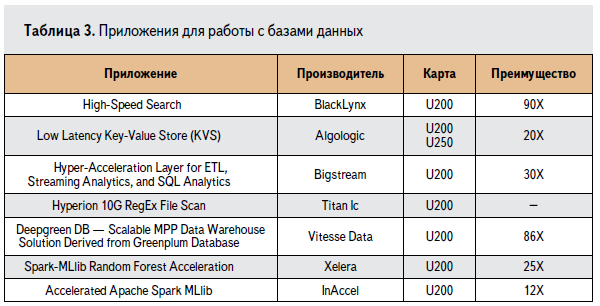
____Для карт-ускорителей Alveo имеется ряд готовых решений, приведённых в таблице 3, где также показано преимущество в сравнении с решением на CPU.
Ускорение обработки видеопотоков.
____К 2021 году объём видеотрафика возрастёт на 31% и составит ориентировочно 16 Пбайт/мес., что составит 81% интернет-трафика. Огромный объём видеотрафика подчеркивает недостатки и ограниченность существующей инфраструктуры сетей и хранилищ данных. Поэтому требуются высококачественные видеокодеки, позволяющие уменьшить размер видеопотока и при этом не потерять качество сжимаемого видео.
____Аппаратные видеокодеки, применяемые в отдельных специализированных микросхемах ASIC или GPU, попросту не обеспечивают того качества, которое могут предложить программные кодеки, запущенные на CPU. Улучшение качества видеокодеков сделало программную реализацию на CPU стандартом де-факто в ЦОД, занимающихся транскодированием видео.
____Однако из-за возросшего объёма видеотрафика ЦОД и программные кодеки становятся всё более сложными, при этом масштабирование существующих решений на базе CPU не может удовлетворить спрос ввиду возрастающей стоимости и потребляемой энергии. Также CPU не могут обеспечить транскодирование видео в режиме реального времени в ряде приложений, например, таких как потоковое вещание и видеонаблюдение. По прогнозам, к 2021 году видео в режиме реального времени займёт до 13% всего видеотрафика.
____Карты-ускорители Alveo способны помочь решить описанные выше проблемы:

____Для того чтобы пользователи смогли оценить преимущества работы с картами-ускорителями Alveo в задачах обработки видео, компания Xilinx совместно с партнерами подготовила ряд готовых решений, часть из которых приведена в таблице 4. В этой же таблице представлены показатели улучшения производительности в сравнении с CPU.
Пример сохранения совокупной стоимости владения.
____Энергетическая эффективность и преимущества в ускорении приложений с помощью карт-ускорителей Alveo позволяют значительно сократить расходы на оборудование и общую стоимость устройства в сравнении с решением на CPU. Уменьшение расходов связано с меньшей стоимостью аппаратной части, меньшей потребляемой мощностью и затратами на охлаждение, поскольку одна карта-ускоритель Alveo способна заменить несколько CPU.
____Разберём снижение совокупных затрат для трёх вышеперечисленных приложений: машинное обучение, анализ и поиск в базах данных, обработка видео. Приложения, которые раньше требовали 10 000 CPU-серверов, теперь могут быть заменены 2600, 2830 и 2700 серверов с картами-ускорителями Alveo, что сокращает общие совокупные затраты на 58–65%. К тому же расходы на энергопотребление и охлаждение могут быть уменьшены на 59–65%. На рис. 4 отображено уменьшение совокупной стоимости решения для каждого из приложений.

Рис. 4. Сокращение затрат при замене CPU-сервера на сервер с Alveo.
____Одно из преимуществ, не рассмотренное ранее, но имеющее немаловажное значение, — это запас на будущее. Поскольку карта-ускоритель Alveo выполнена с использованием ПЛИС/FPGA, она обладает чрезвычайной гибкостью и адаптируемостью и способна подстраивать свою архитектуру под выполнение любой задачи. В итоге это приводит к тому, что у пользователя нет необходимости менять парк аппаратных средств при выходе новой нейронной сети или нового высокоэффективного видеокодека.
Технические характеристики карт-ускорителей Alveo.
____Карты-ускорители Alveo являются PCIe-совместимыми устройствами с поддержкой PCI Express Gen3 x16. Карта занимает два слота по ширине и может быть либо 3/4 длины, либо полноразмерной по длине, в зависимости от исполнения: с пассивным или активным охлаждением. Прошивка карт-ускорителей для выполнения конкретной задачи может быть выполнена удаленно через PCI Express.

Рис. 5. Блок-диаграмма карт-ускорителей Alveo U200 и U250.
____На рис. 5 показаны основные компоненты карт-ускорителей Alveo U200 или U250.

____В карте установлено четыре планки оперативной памяти 288‑pin DDR4 DIMM. Параметры интерфейса памяти указаны в таблице 5:

____Поддержка операционных систем:
Ресурсы программируемой логики.
____Сердцем карт-ускорителей Alveo U200 и U250 служит микросхема ПЛИС компании Xilinx с архитектурой UltraScale+. ПЛИС, установленные на Alveo U200 и U250, являются специализированными именно для работы только в этих картах и называются XCU200 и XCU250 соответственно. ПЛИС XCU200 и XCU250 выполнены по технологии Stacked Silicon Interconnect (SSI). Применение технологии SSI позволяет достичь рекордной логической ёмкости ПЛИС, пропускной способности и энергоэффективности. Увеличение ёмкости осуществляется за счёт соединения нескольких суперрегионов (Super Logic Regions SLRs). XCU200 содержит три SLR, а XCU250 — четыре SLR.
____Развёртываемая оболочка (shell), предназначенная для управления включением и конфигурированием FPGA через PCIe, находится в статической области/регионе FPGA (используется технология частичного реконфигурирования — partial reconfiguration. Partial Reconfiguration in the Vivado Design Suite. www.xilinx.com/products/design-tools/vivado/implementation/partial-reconfiguration.html). Основная часть ПЛИС относится к динамически реконфигурируемой области и может быть использована разработчиками для развертывания собственных ускорителей.
____О том, как развернуть собственный ускоритель в динамически реконфигурируемой области, можно узнать в руководстве (UG1023. SDAccel Environment User Guide. Xilinx Inc. December 5, 2018.) в разделе “SLR Assignments for Kernels”.
Динамически реконфигурируемые области.
____Динамически реконфигурируемые области предназначены для создания и развёртывания пользовательских ускорителей. На рис. 6 и в таблице 7 показано количество и расположение доступных ресурсов. Дополнительные сведения о различных ресурсах и их возможностях представлены в (XMP451. Product Selection Guide. Data Center Accelerator Cards. Xilinx Inc., 2018.).

Рис. 6. Структура регионов XCU200 и XCU250.

____Подробнее с техническими характеристиками (рабочая температура, влажность, параметры охлаждения и т. д.) карт-ускорителей Alveo U200 и U250 пользователи могут ознакомиться в (DS962. Alveo U200 and U250 Data Center Accelerator Cards Data Sheet. Xilinx Inc. October 2, 2018.).
Alveo — адаптируемые ускорители на FPGA.
Часть 1.
Часть 1.
Михаил Коробков
m.korobkov@inline-ctc.ru
Михаил Кузелин
mike@inline-ctc.ru
m.korobkov@inline-ctc.ru
Михаил Кузелин
mike@inline-ctc.ru
КОМПОНЕНТЫ И ТЕХНОЛОГИИ • № 1 '2019
____Удовлетворение потребностей рынка при использовании процессоров (CPU) или многоядерных процессоров в серверах и центрах обработки данных оказывается затруднительным из-за их возрастающей стоимости, повышенного энергопотребления и размера самих стоек с CPU. Более того, для решения многих задач увеличение количества полностью процессорных серверов не приведёт к достижению желаемой производительности. Ввиду сложностей уменьшения технологического процесса изготовления микросхем не следует особо полагаться на увеличение эффективности за счёт процессоров следующего поколения. Поэтому всё большее внимание уделяется адаптивным ускорителям, которые могут удовлетворить растущие запросы высокопроизводительных вычислений.
Введение.
____В современных условиях, когда всё более совершенные алгоритмы появляются быстрее, чем успевают производиться соответствующие ресурсы с фиксированной функциональностью, такие как ASIC и GPU, рынку необходимы устройства, способные как можно быстрее подстраиваться под изменчивые требования алгоритмов. Карты-ускорители Alveo U200 и U250, созданные на базе самых современных FPGA архитектуры UltraScale+ компании Xilinx, обладают чрезвычайной гибкостью, реконфигурируемостью и адаптируемостью, позволяющей применить их для реализации любых задач.
____Карты-ускорители Alveo специально разработаны для удовлетворения потребностей быстро меняющегося мира высокопроизводительных вычислений ЦОД, что предусматривает достижение 90‑кратного преимущества по сравнению с CPU в таких приложениях, как машинное обучение, видеотранскодинг, поиск и анализ баз данных (WP499. Breathe New Life into Your Data Center with Alveo Adaptable Accelerator Cards — Xilinx Inc. November 19, 2018).
Быстродействие, доступность и адаптируемость.
____Для устранения растущего разрыва между спросом на вычислительные ресурсы и возможностями ЦОД, состоящих только из CPU, компания Xilinx предложила серию специализированных ускорителей Alveo — плат формата PCIe, готовых к установке и работе в ЦОД. На рис. 1 изображена плата-ускоритель Alveo с активным охлаждением (имеется исполнение и с пассивным охлаждением).


Рис. 1. Плата Alveo U250 c активным и пассивным охлаждением.
____Плата-ускоритель — это законченное решение, сочетающее все преимущества микросхем ПЛИС Xilinx:
- быстродействие — самые высокие показатели пропускной способности и минимальной задержки;
- адаптируемость — отвечает существующим и новым возникающим потребностям рынка высокопроизводительных вычислений;
- доступность — готовые приложения, которые могут быть развернуты как на локальном сервере, так и в облаке.
____Перечисленные преимущества делают карты-ускорители Alveo лидером во многих областях высокопроизводительных вычислений и обработки данных:
- широта применения — решение задач машинного обучения, поиска и анализа баз данных, обработка и транскодирование видеопотоков, финансовые вычисления и задачи геномики;
- лучшая производительность и эффективность по сравнению с решениями CPU/GPU — 90‑кратное превосходство над CPU и 5‑кратное над GPU;
- наилучший показатель совокупной стоимости владения (TCO) — сокращение затрат до 65%;
- перспективность — адаптируемость карт-ускорителей Alveo по мере расширения круга решаемых задач.
____Карты-ускорители U200 и U250 уже выпускаются компанией Xilinx, а карта-ускоритель U280, содержащая ПЛИС с высокопроизводительной памятью HBM, будет доступна в ближайшее время. Следующие поколения карт-ускорителей Alveo будут содержать кристаллы с недавно анонсированной архитектурой Versal:
- Коробков М. Новинки Xilinx Developer Forum 2018 // Современная электроника. 2019. № 1.
- WP505. Versal: The First Adaptive Compute Acceleration Platform (ACAP). Xilinx Inc. October 2, 2018.
- Versal. https://www.xilinx.com/products/silicon-devices/acap/versal.html
или адаптируемой платформой ускорения вычислений (ACAP), обладающие ещё большими показателями производительности и эффективности. Например, вычислительные модули AI Engines в архитектуре Versal позволят ускорить приложения машинного обучения до 20 раз.
Быстродействие.
____Карты-ускорители уникальны, поскольку обладают сразу двумя важными достоинствами: высокой пропускной способностью и маленькой задержкой для широкого круга приложений, разворачиваемых в ЦОД. Решения на базе CPU и GPU обычно предполагают компромисс между задержкой и пропускной способностью ввиду ограничений их жесткой архитектуры и программно управляемого потока данных.

Рис. 2. Преимущество карт-ускорителей Alveo перед решениями на CPU.
На рис. 2 отображены некоторые показатели преимущества карт-ускорителей Alveo над решениями на CPU для наиболее ключевых приложений, разворачиваемых в ЦОД. Более детальное описание преимуществ будет приведено далее в статье.
Адаптируемость.
____В отличие от CPU и GPU карты-ускорители Alveo имеют аппаратную адаптируемость, в том смысле, что лежащее в основе аппаратное обеспечение (программируемая логическая интегральная схема — ПЛИС, FPGA) может быть сконфигурировано (реконфигурировано) в зависимости от выполняемой задачи. Решения на CPU и GPU могут предложить только гибкость в плане программного обеспечения, поскольку их аппаратная структура имеет фиксированную архитектуру, которую нельзя изменить. И если решаемая задача такова, что плохо «ложится» на фиксированную архитектуру CPU или GPU, то в этом случае достижение высокой производительности от аппаратуры невозможно.
____Гибкость архитектуры карт-ускорителей Alveo даёт следующие преимущества:
- наивысшая используемость оборудования в ЦОД — ускорение широчайшего круга задач при меньшем количестве аппаратуры;
- перспективность оборудования — адаптация под новые задачи без необходимости замены оборудования (рис. 3).

Рис. 3. Адаптируемость Alveo: меньшее количество обновлений оборудования.
____Для разработчиков, желающих построить и адаптировать собственные приложения на картах-ускорителях Alveo, компания Xilinx представляет специализированную среду разработки SDAccel Development environment (www.xilinx.com/products/design-tools/software-zone/sdaccel.html).
Доступность.
____Для того чтобы предоставить пользователям возможность оценить все преимущества карт-ускорителей Alveo, компания Xilinx совместно с партнерами подготовила ряд приложений. Приложения покрывают ключевые особенности и направления применения карт-ускорителей Alveo, включая развертывание обученных нейронных сетей для задач машинного обучения, транскодинг видеопотоков, анализ и поиск по базам данных, геномику и вычисления в области финансов. В таблице 1 приведена часть списка приложений, доступных на картах-ускорителях Alveo. С полным списком доступных приложений можно ознакомиться на сайте Xilinx (Alveo Accelerator Card Applications. www.xilinx.com/products/acceleration-solutions.html).

____Для апробирования преимуществ технологий и изделий компании Xilinx облачные сервисы, такие как AWS, Nimbix, Alibaba, Baidu, Tancent и Huawei, уже подготовили услугу FaaS (FPGA as a Service) — «FPGA как сервис». Облачные решения предлагают пользователю легкий доступ к апробированию решений Xilinx для ускорения приложений пользователя на картах-ускорителях Alveo, без необходимости разворачивать у себя какой-либо сервер для тестирования преимуществ данных карт. При получении удовлетворительных результатов пользователь может применить карты-ускорители Alveo в собственном сервере. Локальное развертывание решения в общем случае может быть необходимо по различным причинам — например, в случае приложений, где критичным является время вычислений и получение результата.
____Более подробно о сервисе FaaS с использованием продуктов компании Xilinx можно ознакомиться в (Accelerated Cloud Services. www.xilinx.com/products/design-tools/cloud-based-acceleration.html).
Примеры приложений для ЦОД.
____Для обзора преимуществ быстродействия, доступности и адаптируемости карт-ускорителей Alveo проанализируем несколько приложений для ЦОД:
- машинное обучение на обученных нейронных сетях;
- анализ и поиск по базам данных;
- обработка видео.
Ускорение задач машинного обучения на Alveo.
____Многие компании получили огромные преимущества после адаптации машинного обучения под свои задачи и технологии. К ним относятся, например, медицинская диагностика, сетевая безопасность, автономное вождение, обработка изображений со спутников. Машинное обучение само по себе является широкой и динамически развивающейся областью. Вместе с тем оно имеет два уникальных этапа:
- Training — обучение нейронной сети для выполнения специализированной задачи;
- Inference — разворачивание натренированной нейронной сети для решения задачи в реальном времени.
____Оба этапа чрезвычайно вычислительно затратны. Как следствие, решение на базе только одних CPU оказывается неперспективным ввиду того, что такое решение не может достичь необходимой производительности и требуемой задержки. Да и стоимость и энергозатраты подобного решения становятся несоизмеримо высоки.
____Решения на базе GPU хорошо подходят для задачи обучения нейронной сети, поскольку архитектура GPU содержит большое количество вычислительных модулей, реализующих операции с плавающей запятой. Однако при развёртывании обученной нейронной сети GPU оказываются во многом неподходящим решением. Анализ различий между обучением и развертыванием нейронных сетей позволяет выявить следующие причины, по которым решения на базе GPU могут оказаться неподходящими для этапа Inference:
- задержка является критически важным параметром для Inference;
- соотношение количества вычислений к количеству обращений к памяти значительно меньше для Inference;
- для Inference возможно использовать данные меньшей разрядности.
____Комбинация необходимости быстрого отклика с более высоким коэффициентом передачи данных для вычисления результатов становится реальным вызовом для применения GPU в области развертывания обученных нейронных сетей. Компания Nvidia опубликовала результаты, которые показали, что их флагман Tesla V100 может обработать только 870 изображений/с для сети GoogleNet v1 Batch = 1, что составляет лишь ~2% от теоретической производительности V100 в 40 тыс. изображений/с для обученной сети GoogleNet v1, даже при использовании памяти HBM с пропускной способностью 900 Гбайт/с (Nvidia white paper, Nvidia ai inference platform. www.nvidia.com/en-us/data-center/resources/inference-technical-overview). Для сравнения: развернутая на карте-ускорителе Alveo нейронная сеть GoogLeNet показала производительность, равную 50% от теоретически достижимой при Batch = 1.
____По мере развития нейронных сетей архитектура GPU, вероятно, будет становиться всё более сложной. Как пример — поддержка GPU только определенного типа данных. В случае если необходимо работать с данными меньшей разрядности или произвольной разрядности для улучшения показателей эффективности и пропускной способности, пользователь вынужден дождаться появления новой карты, прежде чем сможет воспользоваться преимуществами реализации нейронной сети с уменьшенной или произвольной точностью. Как результат и как описано в разделе «Адаптируемость» и изображено на рис. 3, решения на базе GPU требуют частого обновления аппаратной части, что приводит к удорожанию оборудования и решения в целом.
____Карты-ускорители Alveo являются более подходящим решением по ряду причин:
- сверхнизкая детерминированная задержка;
- способность к адаптации аппаратной части под любые задачи машинного обучения;
- способность к реконфигурированию аппаратной части по мере развития приложений машинного обучения и нейронных сетей без необходимости покупки нового оборудования;
- поддержка данных любой точности и разрядности без покупки дополнительного оборудования;
- возможность прямого подключения к сети без использования центрального процессора.
____Для того чтобы специалисты могли воспользоваться преимуществами карт-ускорителей Alveo в задачах ML Inference, компанией Xilinx и партнерами было подготовлено несколько решений. Примеры некоторых решений и их сравнение с CPU приведены в таблице 2.

____Для того чтобы лучше понять преимущества карт-ускорителей Alveo в задачах ML Inference, рассмотрим специализированный инструмент ML Suite, разработанный компанией Xilinx для решения именно этой задачи.
Xilinx ML Suite.
____Компания Xilinx создала ML Suite для быстрого развертывания своих ускорителей для работы с обученными свёрточными нейронными сетями (Сonvolution Neural Network — CNN, класс сетей для машинного обучения, используемых для классификации изображений и детектирования объектов). Сердцем ML Suite является вычислительный модуль xDNN (будет рассмотрен далее), реализованный в микросхемах ПЛИС Xilinx, и специализированное промежуточное программное обеспечение xfDNN, позволяющее работать с современными фреймворками машинного обучения через API на языках Python и C++. Подробнее о структуре ML Suite, xfDNN и xDNN будет написано во второй части статьи.
Ускорение анализа и поиска по базам данных.
____Анализ данных — важный инструмент для предприятий. По сути, анализ данных — это получение релевантных данных (поиск), в основном хранящихся в объёмных базах данных, обработка/анализ этих данных для получения информации. Предприятиям нужна возможность быстрее обрабатывать и анализировать большие и неструктурированные наборы данных. Поиск решения этой проблемы при масштабировании вычислительных узлов, содержащих только CPU, может стать проблемой ввиду увеличения стоимости, энергопотребления и плохой масштабируемости данного подхода.
____GPU используются для ускорения ограниченного круга задач поиска и анализа баз данных. Однако преимущества GPU весьма ограничены их фиксированной архитектурой. Многие требования конечных приложений поиска и анализа баз данных расходятся с сегодняшней архитектурой GPU:
- низкое соотношение вычислений к передаче данных;
- большое разнообразие моделей потоков данных;
- прямой доступ к сети передачи данных — ключевое преимущество ускорителей.
____В сравнении с GPU карты-ускорители Alveo имеют возможность аппаратного конфигурирования (реконфигурирования) для выполнения специфической задачи, а возможность прямого подключения к сети передачи данных делает их идеальным ускорителем для широкого круга задач анализа и поиска в базах данных. Эти преимущества приводят к более быстрому решению, требующему меньше аппаратного обеспечения и потребляемой мощности, что в итоге положительно сказывается на стоимости решения в целом.

____Для карт-ускорителей Alveo имеется ряд готовых решений, приведённых в таблице 3, где также показано преимущество в сравнении с решением на CPU.
Ускорение обработки видеопотоков.
____К 2021 году объём видеотрафика возрастёт на 31% и составит ориентировочно 16 Пбайт/мес., что составит 81% интернет-трафика. Огромный объём видеотрафика подчеркивает недостатки и ограниченность существующей инфраструктуры сетей и хранилищ данных. Поэтому требуются высококачественные видеокодеки, позволяющие уменьшить размер видеопотока и при этом не потерять качество сжимаемого видео.
____Аппаратные видеокодеки, применяемые в отдельных специализированных микросхемах ASIC или GPU, попросту не обеспечивают того качества, которое могут предложить программные кодеки, запущенные на CPU. Улучшение качества видеокодеков сделало программную реализацию на CPU стандартом де-факто в ЦОД, занимающихся транскодированием видео.
____Однако из-за возросшего объёма видеотрафика ЦОД и программные кодеки становятся всё более сложными, при этом масштабирование существующих решений на базе CPU не может удовлетворить спрос ввиду возрастающей стоимости и потребляемой энергии. Также CPU не могут обеспечить транскодирование видео в режиме реального времени в ряде приложений, например, таких как потоковое вещание и видеонаблюдение. По прогнозам, к 2021 году видео в режиме реального времени займёт до 13% всего видеотрафика.
____Карты-ускорители Alveo способны помочь решить описанные выше проблемы:
- высокая вычислительная ёмкость — одна карта Alveo может заменить несколько CPU;
- отличная адаптируемость — поддержка многих современных кодеков;
- производительность в режиме реального времени — поддержка транскодирования видео в режиме реального времени.

____Для того чтобы пользователи смогли оценить преимущества работы с картами-ускорителями Alveo в задачах обработки видео, компания Xilinx совместно с партнерами подготовила ряд готовых решений, часть из которых приведена в таблице 4. В этой же таблице представлены показатели улучшения производительности в сравнении с CPU.
Пример сохранения совокупной стоимости владения.
____Энергетическая эффективность и преимущества в ускорении приложений с помощью карт-ускорителей Alveo позволяют значительно сократить расходы на оборудование и общую стоимость устройства в сравнении с решением на CPU. Уменьшение расходов связано с меньшей стоимостью аппаратной части, меньшей потребляемой мощностью и затратами на охлаждение, поскольку одна карта-ускоритель Alveo способна заменить несколько CPU.
____Разберём снижение совокупных затрат для трёх вышеперечисленных приложений: машинное обучение, анализ и поиск в базах данных, обработка видео. Приложения, которые раньше требовали 10 000 CPU-серверов, теперь могут быть заменены 2600, 2830 и 2700 серверов с картами-ускорителями Alveo, что сокращает общие совокупные затраты на 58–65%. К тому же расходы на энергопотребление и охлаждение могут быть уменьшены на 59–65%. На рис. 4 отображено уменьшение совокупной стоимости решения для каждого из приложений.

Рис. 4. Сокращение затрат при замене CPU-сервера на сервер с Alveo.
____Одно из преимуществ, не рассмотренное ранее, но имеющее немаловажное значение, — это запас на будущее. Поскольку карта-ускоритель Alveo выполнена с использованием ПЛИС/FPGA, она обладает чрезвычайной гибкостью и адаптируемостью и способна подстраивать свою архитектуру под выполнение любой задачи. В итоге это приводит к тому, что у пользователя нет необходимости менять парк аппаратных средств при выходе новой нейронной сети или нового высокоэффективного видеокодека.
Технические характеристики карт-ускорителей Alveo.
____Карты-ускорители Alveo являются PCIe-совместимыми устройствами с поддержкой PCI Express Gen3 x16. Карта занимает два слота по ширине и может быть либо 3/4 длины, либо полноразмерной по длине, в зависимости от исполнения: с пассивным или активным охлаждением. Прошивка карт-ускорителей для выполнения конкретной задачи может быть выполнена удаленно через PCI Express.

Рис. 5. Блок-диаграмма карт-ускорителей Alveo U200 и U250.
____На рис. 5 показаны основные компоненты карт-ускорителей Alveo U200 или U250.

____В карте установлено четыре планки оперативной памяти 288‑pin DDR4 DIMM. Параметры интерфейса памяти указаны в таблице 5:
- Сетевые интерфейсы. Обе карты-ускорителя Alveo U200 и Alveo U250 имеют два 100G-интерфейса, каждый из которых подключён к 4‑lane QSFP28‑соединителю. QSFP-соединители не поддерживаются текущей версией программной оболочки (shell).
- USB-порт. Карты-ускорители имеют USB-порт микро-USB.
- Проверенные совместимые серверы. Карты-ускорители были проверены и протестированы на следующих серверах (табл. 6).

____Поддержка операционных систем:
- CentOS 7.4/7.5;
- RHEL 7.4/7.5;
- Ubuntu 16.04.4.
Ресурсы программируемой логики.
____Сердцем карт-ускорителей Alveo U200 и U250 служит микросхема ПЛИС компании Xilinx с архитектурой UltraScale+. ПЛИС, установленные на Alveo U200 и U250, являются специализированными именно для работы только в этих картах и называются XCU200 и XCU250 соответственно. ПЛИС XCU200 и XCU250 выполнены по технологии Stacked Silicon Interconnect (SSI). Применение технологии SSI позволяет достичь рекордной логической ёмкости ПЛИС, пропускной способности и энергоэффективности. Увеличение ёмкости осуществляется за счёт соединения нескольких суперрегионов (Super Logic Regions SLRs). XCU200 содержит три SLR, а XCU250 — четыре SLR.
____Развёртываемая оболочка (shell), предназначенная для управления включением и конфигурированием FPGA через PCIe, находится в статической области/регионе FPGA (используется технология частичного реконфигурирования — partial reconfiguration. Partial Reconfiguration in the Vivado Design Suite. www.xilinx.com/products/design-tools/vivado/implementation/partial-reconfiguration.html). Основная часть ПЛИС относится к динамически реконфигурируемой области и может быть использована разработчиками для развертывания собственных ускорителей.
____О том, как развернуть собственный ускоритель в динамически реконфигурируемой области, можно узнать в руководстве (UG1023. SDAccel Environment User Guide. Xilinx Inc. December 5, 2018.) в разделе “SLR Assignments for Kernels”.
Динамически реконфигурируемые области.
____Динамически реконфигурируемые области предназначены для создания и развёртывания пользовательских ускорителей. На рис. 6 и в таблице 7 показано количество и расположение доступных ресурсов. Дополнительные сведения о различных ресурсах и их возможностях представлены в (XMP451. Product Selection Guide. Data Center Accelerator Cards. Xilinx Inc., 2018.).

Рис. 6. Структура регионов XCU200 и XCU250.

____Подробнее с техническими характеристиками (рабочая температура, влажность, параметры охлаждения и т. д.) карт-ускорителей Alveo U200 и U250 пользователи могут ознакомиться в (DS962. Alveo U200 and U250 Data Center Accelerator Cards Data Sheet. Xilinx Inc. October 2, 2018.).
Продолжение следует...
Viktor2312- RIP
- Сообщения : 15492
Дата регистрации : 2012-08-10
Возраст : 45
Откуда : Пятигорск

 Похожие темы
Похожие темы» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
» Статьи, заметки, очерки, разное...
Страница 1 из 1
Права доступа к этому форуму:
Вы не можете отвечать на сообщения|
|
|